Массивы объектов
Во всех рассмотренных примерах этой главы нам встречались массивы, элементы которых имели только простые значимые типы. В реальных программах массивы объектов и других ссылочных типов встречаются не менее часто. Каков бы ни был тип элементов, большой разницы при работе с массивами нет. Но один важный нюанс все же есть, и его стоит отметить. Он связан с инициализацией элементов по умолчанию. Уже говорилось о том, что компилятор не следит за инициализацией элементов массива и доверяет инициализации, выполненной конструктором массива по умолчанию. Но для массивов ссылочного типа инициализация по умолчанию присваивает ссылкам значение Null. Это означает, что создаются только ссылки, но не сами объекты. По этой причине, пока не будет проведена настоящая инициализация с созданием объектов и заданием ссылок на конкретные объекты, работать с массивом ссылочного типа будет невозможно.
Рассмотрим детали этой проблемы на примере. Определим достаточно простой и интуитивно понятный класс, названный Winners, свойства которого задают имя победителя и его премию, а методы позволяют установить размер премии для каждого победителя и распечатать его свойства. Приведу код, описывающий этот класс:
/// <summary> /// Класс победителей с именем и премией /// </summary> public class Winners { //поля класса string name; int price; //статическое или динамическое поле rnd? //static Random rnd = new Random(); Random rnd = new Random(); // динамические методы public void SetVals(string name) { this.name = name; this.price = rnd.Next(5,10)* 1000; }//SetVals public void PrintWinner(Winners win) { Console.WriteLine("Имя победителя: {0}," + " его премия - {1}", win.name, win.price); }//PrintWinner }//class Winners
Коротко прокомментирую этот текст.
Свойство name описывает имя победителя, а свойство price - величину его премии.Свойство rnd необходимо при работе со случайными числами.Метод SetVals выполняет инициализацию. Он присваивает полю name значение, переданное в качестве аргумента, и полю price - случайное значение.Метод PrintWinner - метод печати свойств класса. Без подобного метода не обходится ни один класс.В классе появится еще один статический метод InitAr, но о нем скажу чуть позже.
Пусть теперь в одном из методов нашего тестирующего класса Testing предполагается работа с классом Winners, начинающаяся с описания победителей. Естественно, задается массив, элементы которого имеют тип Winners. Приведу начало тестирующего метода, в котором дано соответствующее объявление:
public void TestWinners() { //массивы объектов int nwin = 3; Winners[] wins = new Winners[nwin]; string[] winames = {"Т. Хоар", "Н. Вирт", "Э. Дейкстра"};
В результате создан массив wins, состоящий из объектов класса Winners. Что произойдет, если попытаться задать значения полей объектов, вызвав специально созданный для этих целей метод SetVals? Рассмотрим фрагмент кода, осуществляющий этот вызов:
//создание значений элементов массива for(int i=0; i < wins.Length; i++) wins[i].SetVals(winames[i]);
На этапе выполнения будет сгенерировано исключение - нулевая ссылка. Причина понятна: хотя массив wins и создан, но это массив ссылок, имеющих значение null. Сами объекты, на которые должны указывать ссылки, не создаются в момент объявления массива ссылочного типа. Их нужно создавать явно. Ситуация аналогична объявлению массива массивов. И там необходим явный вызов конструктора для создания каждого массива на внутреннем уровне.
Как же создавать эти объекты? Конечно, можно возложить эту обязанность на пользователя, объявившего массив wins, - пусть он и создаст экземпляры для каждого элемента массива. Правильнее все-таки иметь в классе соответствующий метод. Метод должен быть статическим, чтобы его можно было вызывать еще до того, как созданы экземпляры класса, поскольку метод предназначен для создания этих самых экземпляров. Так в нашем классе появился статический метод InitAr:
//статический метод public static Winners[] InitAr(Winners[] Winar) { for(int i=0; i < Winar.Length; i++) Winar[i] = new Winners(); return(Winar); }//InitAr
Методу передается массив объектов, возможно, с нулевыми ссылками. Он возвращает тот же массив, но уже с явно определенными ссылками на реально созданные объекты. Теперь достаточно вызвать этот метод, после чего можно спокойно вызывать и метод SetVals. Вот как выглядит правильная последовательность вызовов методов класса Winners:
Winners.InitAr(wins); //создание значений элементов массива for(int i=0; i < wins.Length; i++) wins[i].SetVals(winames[i]); //печать значений элементов массива for(int i=0; i < wins.Length; i++) wins[i].PrintWinner(wins[i]); }//TestWinners
Теперь все корректно, массивы создаются, элементы заполняются нужными значениями, их можно распечатать:
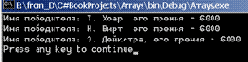
Рис. 12.5. Печать элементов массива wins
Обратите внимание, что всем победителям назначена одна и та же премия. Хотя понятно, что дело в программной ошибке, но в ней можно видеть и знак свыше. Коль скоро для победителей выбраны такие имена, почитаемые всеми программистами, то негоже пытаться расставить их по ранжиру даже в примере. Что же касается ошибки, то она связана с тем, что в данном случае свойство rnd следует сделать статическим, чтобы оно было одно на все экземпляры класса. В тексте описания варианта класса приведены оба варианта объявления свойства, один из которых закомментирован. |
Массивы. Семантика присваивания
Преобразования между классами массивов и родительскими классами Array и Object уже рассматривались. А существуют ли другие преобразования между классами массивов? Что происходит при присваивании x=e; (передаче аргументов в процедуру), если x и e - это массивы разных классов? Возможно ли присваивание? Ответ на этот вопрос положительный, хотя накладываются довольно жесткие ограничения на условия, когда такие преобразования допустимы. Известно, например, что между классами Int и Object существуют взаимные преобразования - в одну сторону явное, в другую неявное. А вот между классами Int[] и Object[] нет ни явных, ни неявных преобразований. С другой стороны, такое преобразование существует между классами String[] и Object[]. В чем же тут дело, и где логика? Запомните, главное ограничение на возможность таких преобразований состоит в том, что элементы массивов должны иметь ссылочный тип. А теперь притянем сюда логику. Крайне желательно обеспечить возможность проведения преобразований между массивами, элементы которых принадлежат одному семейству классов, связанных отношением наследования. Такая возможность и была реализована. А вот для массивов с элементами значимых типов подобную же возможность не захотели или не смогли реализовать.
Сформулируем теперь точные правила, справедливые для присваивания и передачи аргументов в процедуру. Для того, чтобы было возможным неявное преобразование массива с элементами класса S в массив с элементами класса T, необходимо выполнение следующих условий:
классы S и T должны быть ссылочного типа;размерности массивов должны совпадать;должно существовать неявное преобразование элементов класса S в элементы класса T.
Заметьте, если S - это родительский класс, а T - его потомок, то для массивов одной размерности остальные условия выполняются. Вернемся теперь к примеру с классами Int[], String[] и Object[]. Класс Int не относится к ссылочным классам, и потому преобразования класса Int[] в Object[] не существует. Класс string является ссылочным классом и потомком класса Object, а потому существует неявное преобразование между классами String[] и Object[].
Правило для явного преобразования можно сформулировать, например, так. Если существует неявное преобразование массива с элементами класса S в массив с элементами класса T, то существует явное преобразование массива с элементами класса T в массив с элементами класса S.
Для демонстрации преобразований между массивами написана еще одна процедура печати. Вот ее текст:
public static void PrintArObj(string name,object[] A) { Console.WriteLine(name); foreach (object item in A ) Console.Write("\t {0}", item); Console.WriteLine(); }//PrintArObj
Как видите, формальный аргумент этой процедуры принадлежит классу Object[]. При ее вызове фактическими аргументами могут быть массивы, удовлетворяющие выше указанным условиям. Вот пример кода, в котором вызывается эта процедура. В этом же фрагменте показаны и присваивания массива одного класса другому, где выполняются явные и неявные преобразования массивов.
public void TestMas() { string[] winames = {"Т. Хоар", "Н. Вирт", "Э. Дейкстра"}; Arrs.PrintArObj("winames", winames); object[] cur = new object[5]; cur = winames; Arrs.PrintArObj("cur", cur); winames = (string[])cur; Arrs.PrintArObj("winames", winames); }//TestMas
Взгляните на результаты работы этой процедуры.
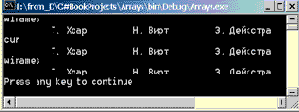
Рис. 12.6. Семантика присваивания и преобразования массивов
Приступая к описаниям массивов, я полагал, что 10 страниц одной лекции будет вполне достаточно. Оказалось, что массивы C# более интересны. Надеюсь, с этим согласятся и читатели.
Метаданные
Переносимый исполняемый PE-файл является самодокументируемым файлом и, как уже говорилось, содержит и код, и метаданные, описывающие код. Файл начинается с манифеста и включает в себя описание всех классов, хранимых в PE-файле, их свойств, методов, всех аргументов этих методов - всю необходимую CLR информацию. Поэтому помимо PE-файла не требуется никаких дополнительных файлов и записей в реестр - вся нужная информация извлекается из самого файла. Среди классов библиотеки FCL имеется класс Reflection, методы которого позволяют извлекать необходимую информацию. Введение метаданных - не только важная техническая часть CLR, но это также часть новой идеологии разработки программных продуктов. Мы увидим, что и на уровне языка C# самодокументированию уделяется большое внимание.
Мы увидим также, что при проектировании класса программист может создавать собственные атрибуты, добавляемые к метаданным PE-файла. Клиенты этого класса могут, используя класс Reflection, получать эту дополнительную информацию, и на ее основании принимать соответствующие решения.
На рис. 1.1 показаны результаты дизассемблирования PE-файла простого консольного приложения с именем Account, включающего три класса: Account, Testing и Class1. Дизассемблер структурирует информацию, хранимую в метаданных, и показывает ее в типичном формате дерева. Как обычно, это дерево можно сжимать или раскрывать, демонстрируя детали класса. Значки, приписываемые каждому узлу дерева, характеризуют тип узла - класс, свойство, метод, описание. Двойной щелчок кнопки мыши на этом узле позволяет раскрыть его. При раскрытии метода можно получить его код. На рис. 1.1 показан код метода add из класса Account.
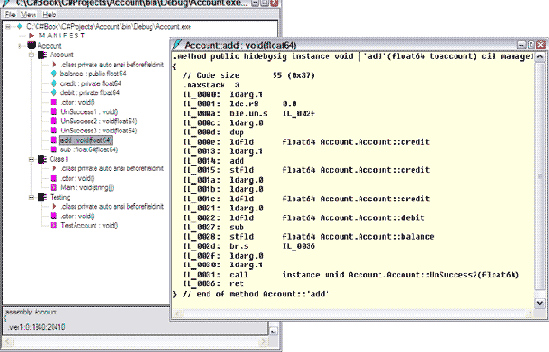
Рис. 1.1. Пример структуры PE-файла, задающего сборку
Метод Флойда и утверждения Assert
Лет двадцать назад большие надежды возлагались на формальные методы доказательства правильности программ, позволяющие доказывать корректность программ аналогично доказательству теорем. Реальные успехи формальных доказательств невелики. Построение такого доказательства не проще написания корректной программы, а ошибки столь же возможны и часты, как и ошибки программирования. Тем не менее, эти методы оказали серьезное влияние на культуру проектирования корректных программ, появление в практике программирования понятий предусловия и постусловия, инвариантов и других важных понятий.
Одним из методов доказательства правильности программ был метод Флойда, при котором программа разбивалась на участки, окаймленные утверждениями - булевскими выражениями (предикатами). Истинность начального предиката должна была следовать из входных данных программы. Затем для каждого участка доказывалось, что из истинности предиката, стоящего в начале участка, после завершения выполнения соответствующего участка программы гарантируется истинность следующего утверждения - предиката в конце участка. Конечный предикат описывал постусловие программы.
Схема Флойда используется на практике, по крайней мере, программистами, имеющими вкус к строгим методам доказательства. Утверждения становятся частью программного текста. Само доказательство может и не проводиться: чаще всего у программиста есть уверенность в справедливости расставленных утверждений и убежденность, что при желании он мог бы провести и строгое доказательство. В C# эта схема поддерживается тем, что классы Debug и Trace имеют метод Assert, аргументом которого является утверждение. Что происходит, когда вычисление достигает соответствующей точки и вызывается метод Assert? Если истинно булево выражение в Assert, то вычисления продолжаются, не оказывая никакого влияния на нормальный ход вычислений. Если оно ложно, то корректность вычислений под сомнением, их выполнение приостанавливается и появляется окно с уведомлением о произошедшем событии, что показано на рис. 23.3.
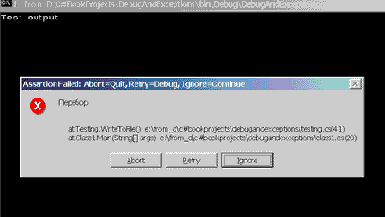
Рис. 23.3. Нарушение утверждения Assert
В этой ситуации у программиста есть несколько возможностей:
прервать выполнение, нажав кнопку Abort;перейти в режим отладки (Retry);продолжить вычисления, проигнорировав уведомление.
В последнем случае сообщение о возникшей ошибке будет послано всем слушателям коллекции TraceListenerCollection.
Рассмотрим простой пример, демонстрирующий нарушение утверждения:
public void WriteToFile() { Stream myFile = new FileStream("TestFile.txt",FileMode.Create,FileAccess.Write); TextWriterTraceListener myTextListener = new TextWriterTraceListener(myFile); int y = Debug.Listeners.Add(myTextListener); TextWriterTraceListener myWriter = new TextWriterTraceListener(System.Console.Out); Trace.Listeners.Add(myWriter); Trace.AutoFlush = true; Trace.WriteLine("автоматический вывод из буфера:" + Trace.AutoFlush); int x = 22; Trace.Assert(x<=21, "Перебор"); myWriter.WriteLine("Вывод только на консоль"); //Trace.Flush(); //Вывод только в файл byte[] buf = {(byte)'B',(byte)'y'}; myFile.Write(buf,0, 2); myFile.Close(); }
Как и в предыдущем примере, здесь создаются два слушателя, направляющие вывод отладочных сообщений на консоль и в файл. Когда произошло нарушение утверждения Assert, оно было проигнорировано, но сообщение о нем автоматически было направлено всем слушателям. Метод также демонстрирует возможность параллельной работы с консолью и файлом. На рис. 23.4 показаны результаты записи в файл:
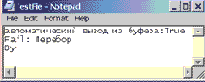
Рис. 23.4. Файл с записью сообщения о нарушении утверждения Assert
Вариацией метода Assert является метод Fail, всегда приводящий к появлению окна с сообщением о нарушении утверждения, проверка которого осуществляется обычным программным путем.
Метод Format
Метод Format в наших примерах встречался многократно. Всякий раз, когда выполнялся вывод результатов на консоль, неявно вызывался и метод Format. Рассмотрим оператор печати:
Console.WriteLine("s1={0}, s2={1}", s1,s2);
Здесь строка, задающая первый аргумент метода, помимо обычных символов, содержит форматы, заключенные в фигурные скобки. В данном примере используется простейший вид формата - он определяет объект, который должен быть подставлен в участок строки, занятый данным форматом. Помимо неявных вызовов, нередко возникает необходимость явного форматирования строки.
Давайте рассмотрим общий синтаксис как самого метода Format, так и используемых в нем форматов. Метод Format, как и большинство методов, является перегруженным и может вызываться с разным числом параметров. Первый необязательный параметр метода задает провайдера, определяющего национальные особенности, которые используются в процессе форматирования. В качестве такого параметра должен быть задан объект, реализующий интерфейс System.IFormatProvider. Если этот параметр не задан, то используется культура, заданная по умолчанию. Вот примеры двух реализаций этого метода:
public static string Format(string, object); public static string Format(IFormatProvider, string, params object[]);
Параметр типа string задает форматируемую строку. Заданная строка содержит один или несколько форматов, они распознаются за счет окружающих формат фигурных скобок. Число форматов, вставленных в строку, определяет и число объектов, передаваемых при вызове метода Format. Каждый формат определяет форматирование объекта, на который он ссылается и который, после преобразования его в строку, будет подставлен в результирующую строку вместо формата. Метод Format в качестве результата возвращает переданную ему строку, где все спецификации формата заменены строками, полученными в результате форматирования объектов.
Общий синтаксис, специфицирующий формат, таков:
{N [,M [:<коды_форматирования>]]}
Обязательный параметр N задает индекс объекта, заменяющего формат. Можно считать, что методу всегда передается массив объектов, даже если фактически передан один объект. Индексация объектов начинается с нуля, как это принято в массивах. Второй параметр M, если он задан, определяет минимальную ширину поля, которое отводится строке, вставляемой вместо формата. Третий необязательный параметр задает коды форматирования, указывающие, как следует форматировать объект. Например, код C (Currency) говорит о том, что параметр должен форматироваться как валюта с учетом национальных особенностей представления. Код P (Percent) задает форматирование в виде процентов с точностью до сотой доли.
Все становится ясным, когда появляются соответствующие примеры. Вот они:
public void TestFormat() { //метод Format int x=77; string s= string.Format("x={0}",x); Console.WriteLine(s + "\tx={0}",x); s= string.Format("Итого:{0,10} рублей",x); Console.WriteLine(s); s= string.Format("Итого:{0,6:######} рублей",x); Console.WriteLine(s); s= string.Format("Итого:{0:P} ",0.77); Console.WriteLine(s); s= string.Format("Итого:{0,4:C} ",77.77); Console.WriteLine(s); //Национальные особенности System.Globalization.CultureInfo ci = new System.Globalization.CultureInfo("en-US"); s= string.Format(ci,"Итого:{0,4:C} ",77.77); Console.WriteLine(s); }//TestFormat
Приведу некоторые комментарии к этой процедуре. Вначале демонстрируется, что и явный, и неявный вызовы метода Format дают один и тот же результат. В дальнейших примерах показано использование различных спецификаций формата с разным числом параметров и разными кодами форматирования. В частности, показан вывод процентов и валют. В последнем примере с валютами демонстрируется задание провайдером национальных особенностей. С этой целью создается объект класса CultureInfo, инициализированный так, чтобы он задавал особенности форматирования, принятые в США. Заметьте, класс CultureInfo наследует интерфейс IFormatProvider. Российские национальные особенности форматирования установлены по умолчанию. При необходимости их можно установить таким же образом, как это сделано для США, задав соответственно константу "ru-RU". Результаты работы метода показаны на рис. 14.2.
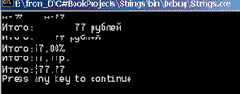
Рис. 14.2. Результаты работы метода Format
Методы Join и Split
Методы Join и Split выполняют над строкой текста взаимно обратные преобразования. Динамический метод Split позволяет осуществить разбор текста на элементы. Статический метод Join выполняет обратную операцию, собирая строку из элементов.
Заданный строкой текст зачастую представляет собой совокупность структурированных элементов - абзацев, предложений, слов, скобочных выражений и т.д. При работе с таким текстом необходимо разделить его на элементы, пользуясь специальными разделителями элементов, - это могут быть пробелы, скобки, знаки препинания. Практически подобные задачи возникают постоянно при работе со структурированными текстами. Методы Split и Join облегчают решение этих задач.
Динамический метод Split, как обычно, перегружен. Наиболее часто используемая реализация имеет следующий синтаксис:
public string[] Split(params char[])
На вход методу Split передается один или несколько символов, интерпретируемых как разделители. Объект string, вызвавший метод, разделяется на подстроки, ограниченные этими разделителями. Из этих подстрок создается массив, возвращаемый в качестве результата метода. Другая реализация позволяет ограничить число элементов возвращаемого массива.
Синтаксис статического метода Join таков:
public static string Join(string delimiters, string[] items )
В качестве результата метод возвращает строку, полученную конкатенацией элементов массива items, между которыми вставляется строка разделителей delimiters. Как правило, строка delimiters состоит из одного символа, который и разделяет в результирующей строке элементы массива items; но в отдельных случаях ограничителем может быть строка из нескольких символов.
Рассмотрим примеры применения этих методов. В первом из них строка представляет сложноподчиненное предложение, которое разбивается на простые предложения. Во втором предложение разделяется на слова. Затем производится обратная сборка разобранного текста. Вот код соответствующей процедуры:
public void TestSplitAndJoin() { string txt = "А это пшеница, которая в темном чулане хранится," +" в доме, который построил Джек!"; Console.WriteLine("txt={0}", txt); Console.WriteLine("Разделение текста на простые предложения:"); string[] SimpleSentences, Words; //размерность массивов SimpleSentences и Words //устанавливается автоматически в соответствии с //размерностью массива, возвращаемого методом Split SimpleSentences = txt.Split(','); for(int i=0;i< SimpleSentences.Length; i++) Console.WriteLine("SimpleSentences[{0}]= {1}", i, SimpleSentences[i]); string txtjoin = string.Join(",",SimpleSentences); Console.WriteLine("txtjoin={0}", txtjoin); Words = txt.Split(',', ' '); for(int i=0;i< Words.Length; i++) Console.WriteLine("Words[{0}]= {1}",i, Words[i]); txtjoin = string.Join(" ",Words); Console.WriteLine("txtjoin={0}", txtjoin); }//TestSplitAndJoin
Результаты выполнения этой процедуры показаны на рис. 14.3.
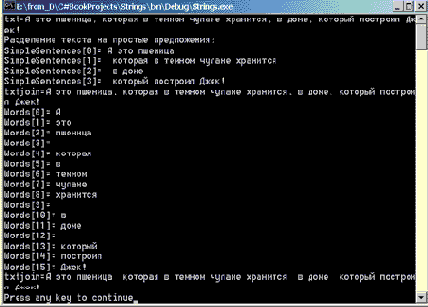
Рис. 14.3. Разбор и сборка строки текста
Обратите внимание, что методы Split и Join хорошо работают, когда при разборе используется только один разделитель. В этом случае сборка действительно является обратной операцией и позволяет восстановить исходную строку. Если же при разборе задается некоторое множество разделителей, то возникают две проблемы:
невозможно при сборке восстановить строку в прежнем виде, поскольку не сохраняется информация о том, какой из разделителей был использован при разборе строки. Поэтому при сборке между элементами вставляется один разделитель, возможно, состоящий из нескольких символов;при разборе двух подряд идущих разделителей предполагается, что между ними находится пустое слово. Обратите внимание в тексте нашего примера, как и положено, после запятой следует пробел. При разборе текста на слова в качестве разделителей указаны символы пробела и запятой. По этой причине в массиве слов, полученном в результате разбора, имеются пустые слова.
Если при разборе предложения на слова использовать в качестве разделителя только пробел, то пустые слова не появятся, но запятая будет являться частью некоторых слов.
Как всегда, есть несколько способов справиться с проблемой. Один из них состоит в том, чтобы написать собственную реализацию этих функций, другой - в корректировке полученных результатов, третий - в использовании более мощного аппарата регулярных выражений, и о нем мы поговорим чуть позже.
Методы класса
Методы класса синтаксически являются обычными процедурами и функциями языка. Их описание удовлетворяет обычным правилам объявления процедур и функций, о чем подробно говорилось в лекции 9. Содержательно методы определяют ту самую абстракцию данных, которую реализует класс. Методы содержат описания операций, доступных над объектами класса. Два объекта одного класса имеют один и тот же набор методов.
Методы класса Graphics
У класса Graphics большое число методов и свойств. Упомяну лишь о некоторых из них. Группа статических методов класса позволяет создать объект этого класса, задавая например описатель (handle) контекста устройства.
Для рисования наиболее важны три группы методов. К первой относится перегруженный метод DrawString, позволяющий выводить тексты в графическом режиме. Вторую группу составляют методы Draw - DrawEllipse, DrawLine, DrawArc и другие, позволяющие цветным пером (объектом класса Pen) рисовать геометрические фигуры: линии, различные кривые, прямоугольники, многоугольники, эллипсы и прочее. К третьей группе относятся методы Fill - FillEllipse, FillPie, FillRectangle и другие, позволяющие нарисовать и закрасить фигуру кистью. Кисти (объекты классов, производных от Brush), могут быть разные - сплошные, узорные, градиентные.
Методы класса Rational
Если поля класса почти всегда закрываются, чтобы скрыть от пользователя представление данных класса, то методы класса всегда имеют открытую часть - те сервисы (службы), которые класс предоставляет своим клиентам и наследникам. Но не все методы открываются. Большая часть методов класса может быть закрытой, скрывая от клиентов детали реализации, необходимые для внутреннего использования. Заметьте, сокрытие представления и реализации делается не по соображениям утаивания того, как реализована система. Чаще всего, ничто не мешает клиентам ознакомиться с полным текстом класса. Сокрытие делается в интересах самих клиентов. При сопровождении программной системы изменения в ней неизбежны. Клиенты не почувствуют на себе негативные последствия изменений, если они делаются в закрытой части класса. Чем больше закрытая часть класса, тем меньше влияние изменений на клиентов класса.
Методы. Перегрузка
Должно ли быть уникальным имя метода в классе? Нет, этого не требуется. Более того, проектирование методов с одним и тем же именем является частью стиля программирования на С++ и стиля C#. Существование в классе методов с одним и тем же именем называется перегрузкой, а сами одноименные методы называются перегруженными.
Перегрузка методов полезна, когда требуется решать подобные задачи с разным набором аргументов. Типичный пример - это нахождение площади треугольника. Площадь можно вычислить по трем сторонам, по двум углам и стороне, по двум сторонам и углу между ними и при многих других наборах аргументов. Считается удобным во всех случаях иметь для метода одно имя, например Square, и всегда, когда нужно вычислить площадь, не задумываясь, вызывать метод Square, передавая ему известные в данный момент аргументы.
Перегрузка характерна и для знаков операций. В зависимости от типов аргументов, один и тот же знак может выполнять фактически разные операции. Классическим примером является знак операции сложения +, который играет роль операции сложения не только для арифметических данных разных типов, но и выполняет конкатенацию строк.
|
О перегрузке операций при определении класса будет подробно сказано в лекции, посвященной классам. |
Перегрузка требует уточнения семантики вызова метода. Когда встречается вызов неперегруженного метода, то имя метода в вызове однозначно определяет, тело какого метода должно выполняться в точке вызова. Когда же метод перегружен, то знания имени недостаточно - оно не уникально. Уникальной характеристикой перегруженных методов является их сигнатура. Перегруженные методы, имея одинаковое имя, должны отличаться либо числом аргументов, либо их типами, либо ключевыми словами (заметьте: с точки зрения сигнатуры, ключевые слова ref и out не отличаются). Уникальность сигнатуры позволяет вызвать требуемый перегруженный метод.
Выше уже были приведены четыре перегруженных метода с именем A, различающиеся по сигнатуре. Эти методы отличаются типами аргументов и ключевым словом params. Когда вызывается метод A с двумя аргументами, то, в зависимости от типа, будет вызываться реализация без ключевого params. Когда же число аргументов больше двух, то работает реализация, позволяющая справиться с заранее не фиксированным числом аргументов. Заметьте, эта реализация может прекрасно работать и для случая двух аргументов, но полезно иметь частные случаи для фиксированного набора аргументов. При поиске подходящего перегруженного метода частные случаи получают предпочтение в сравнении с общим случаем.
Тема поиска подходящего перегруженного метода уже рассматривалась в лекции 3, где шла речь о преобразованиях арифметического типа. Стоит вернуться к примеру, который был рассмотрен в этом разделе и демонстрировал возможность возникновения конфликта: один фактический аргумент требует выбора некоей реализации, для другого - предпочтительнее реализация иная. Для устранения таких конфликтов требуется вмешательство программиста.
Насколько полезна перегрузка методов? Здесь нет экономии кода, поскольку каждую реализацию нужно задавать явно; нет выигрыша по времени - напротив, требуются определенные затраты на поиск подходящей реализации, который может приводить к конфликтам, - к счастью, обнаруживаемым на этапе компиляции. В нашем примере вполне разумно иметь четыре метода с разными именами и осознанно вызывать метод, применимый к данным аргументам. Все-таки есть ситуации, где перегрузка полезна, недаром она широко используется при построении библиотеки FCL. Возьмем, например, класс Convert, у которого 16 методов с разными именами, зависящими от целевого типа преобразования. Каждый из этих 16 методов перегружен, и в свою очередь, имеет 16 реализаций в зависимости от типа источника. Согласитесь, что неразумно было бы иметь в классе Convert 256 методов вместо 16-ти перегруженных методов. Впрочем, также неразумно было бы пользоваться одним перегруженным методом, имеющим 256 реализаций. Перегрузка - это инструмент, который следует использовать с осторожностью и обоснованно.
В заключение этой темы посмотрим, как проводилось тестирование работы с перегруженными методами:
/// <summary> /// Тестирование перегруженных методов A() /// </summary> public void TestLoadMethods() { long u=0; double v =0; A(out u, 7); A(out v, 7.5); Console.WriteLine ("u= {0}, v= {1}", u,v); A(out v,7); Console.WriteLine("v= {0}",v); A(out u, 7,11,13); A(out v, 7.5, Math.Sin(11.5)+Math.Cos(13.5), 15.5); Console.WriteLine ("u= {0}, v= {1}", u,v); }//TestLoadMethods
На рис. 9.3 показаны результаты этого тестирования.
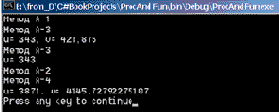
Рис. 9.3. Тестирование перегрузки методов
Методы-свойства
Методы, называемые свойствами (Properties), представляют специальную синтаксическую конструкцию, предназначенную для обеспечения эффективной работы со свойствами. При работе со свойствами объекта (полями) часто нужно решить, какой модификатор доступа использовать, чтобы реализовать нужную стратегию доступа к полю класса. Перечислю пять наиболее употребительных стратегий:
чтение, запись (Read, Write);чтение, запись при первом обращении (Read, Write-once);только чтение (Read-only);только запись (Write-only);ни чтения, ни записи (Not Read, Not Write).
Открытость свойств (атрибут public) позволяет реализовать только первую стратегию. В языке C# принято, как и в других объектных языках, свойства объявлять закрытыми, а нужную стратегию доступа организовывать через методы. Для эффективности этого процесса и введены специальные методы-свойства.
Приведу вначале пример, а потом уточню синтаксис этих методов. Рассмотрим класс Person, у которого пять полей: fam, status, salary, age, health, характеризующих соответственно фамилию, статус, зарплату, возраст и здоровье персоны. Для каждого из этих полей может быть разумной своя стратегия доступа. Возраст доступен для чтения и записи, фамилию можно задать только один раз, статус можно только читать, зарплата недоступна для чтения, а здоровье закрыто для доступа и только специальные методы класса могут сообщать некоторую информацию о здоровье персоны. Вот как на C# можно обеспечить эти стратегии доступа к закрытым полям класса:
public class Person { //поля (все закрыты) string fam="", status="", health=""; int age=0, salary=0; //методы - свойства /// <summary> ///стратегия: Read,Write-once (Чтение, запись при ///первом обращении) /// </summary> public string Fam { set {if (fam == "") fam = value;} get {return(fam);} } /// <summary> ///стратегия: Read-only(Только чтение) /// </summary> public string Status { get {return(status);} } /// <summary> ///стратегия: Read,Write (Чтение, запись) /// </summary> public int Age { set { age = value; if(age < 7)status ="ребенок"; else if(age <17)status ="школьник"; else if (age < 22)status = "студент"; else status = "служащий"; } get {return(age);} } /// <summary> ///стратегия: Write-only (Только запись) /// </summary> public int Salary { set {salary = value;} } }
Рассмотрим теперь общий синтаксис методов-свойств. Пусть name - это закрытое свойство. Тогда для него можно определить открытый метод-свойство (функцию), возвращающую тот же тип, что и поле name. Имя метода обычно близко к имени поля (например, Name). Тело свойства содержит два метода - get и set, один из которых может быть опущен. Метод get возвращает значение закрытого поля, метод set - устанавливает значение, используя передаваемое ему значение в момент вызова, хранящееся в служебной переменной со стандартным именем value. Поскольку get и set - это обычные процедуры языка, то программно можно реализовать сколь угодно сложные стратегии доступа. В нашем примере фамилия меняется, только если ее значение равно пустой строке и это означает, что фамилия персоны ни разу еще не задавалась. Статус персоны пересчитывается автоматически при всяком изменении возраста, явно изменять его нельзя. Вот пример, показывающий, как некоторый клиент создает и работает с полями персоны:
public void TestPersonProps() { Person pers1 = new Person(); pers1.Fam = "Петров"; pers1.Age = 21; pers1.Salary = 1000; Console.WriteLine ("Фам={0}, возраст={1}, статус={2}", pers1.Fam, pers1.Age, pers1.Status); pers1.Fam = "Иванов"; pers1.Age += 1; Console.WriteLine ("Фам={0}, возраст={1}, статус={2}", pers1.Fam, pers1.Age, pers1.Status); }//TestPersonProps
Заметьте, клиент работает с методами-свойствами так, словно они являются настоящими полями, вызывая их как в правой, так и в левой части оператора присваивания. Заметьте также, что с каждым полем можно работать только в полном соответствии с той стратегией, которую реализует данное свойство. Попытка изменения фамилии не принесет успеха, а изменение возраста приведет и к одновременному изменению статуса. На рис. 16.1 показаны результаты работы этой процедуры.

Рис. 16.1. Методы-свойства и стратегии доступа к полям
Многомерные массивы
Уже объяснялось, что разделение массивов на одномерные и многомерные носит исторический характер. Никакой принципиальной разницы между ними нет. Одномерные массивы -это частный случай многомерных. Можно говорить и по-другому: многомерные массивы являются естественным обобщением одномерных. Одномерные массивы позволяют задавать такие математические структуры как векторы, двумерные - матрицы, трехмерные - кубы данных, массивы большей размерности - многомерные кубы данных. Замечу, что при работе с базами данных многомерные кубы, так называемые кубы OLAP, встречаются сплошь и рядом.
В чем особенность объявления многомерного массива? Как в типе указать размерность массива? Это делается достаточно просто, за счет использования запятых. Вот как выглядит объявление многомерного массива в общем случае:
<тип>[, ... ,] <объявители>;
Число запятых, увеличенное на единицу, и задает размерность массива. Что касается объявителей, то все, что сказано для одномерных массивов, справедливо и для многомерных. Можно лишь отметить, что хотя явная инициализация с использованием многомерных константных массивов возможна, но применяется редко из-за громоздкости такой структуры. Проще инициализацию реализовать программно, но иногда она все же применяется. Вот пример:
public void TestMultiArr() { int[,]matrix = {{1,2},{3,4}}; Arrs.PrintAr2("matrix", matrix); }//TestMultiArr
Давайте рассмотрим классическую задачу умножения прямоугольных матриц. Нам понадобится три динамических массива для представления матриц и три процедуры, одна из которых будет заполнять исходные матрицы случайными числами, другая - выполнять умножение матриц, третья - печатать сами матрицы. Вот тестовый пример:
public void TestMultiMatr() { int n1, m1, n2, m2,n3, m3; Arrs.GetSizes("MatrA",out n1,out m1); Arrs.GetSizes("MatrB",out n2,out m2); Arrs.GetSizes("MatrC",out n3,out m3); int[,]MatrA = new int[n1,m1], MatrB = new int[n2,m2]; int[,]MatrC = new int[n3,m3]; Arrs.CreateTwoDimAr(MatrA);Arrs.CreateTwoDimAr(MatrB); Arrs.MultMatr(MatrA, MatrB, MatrC); Arrs.PrintAr2("MatrA",MatrA); Arrs.PrintAr2("MatrB",MatrB); Arrs.PrintAr2("MatrC",MatrC); }//TestMultiMatr
Три матрицы - MatrA, MatrB и MatrC - имеют произвольные размеры, выясняемые в диалоге с пользователем, и использование для их описания динамических массивов представляется совершенно естественным. Метод CreateTwoDimAr заполняет случайными числами элементы матрицы, переданной ему в качестве аргумента, метод PrintAr2 выводит матрицу на печать. Я не буду приводить их код, похожий на код их одномерных аналогов.
Метод MultMatr выполняет умножение прямоугольных матриц. Это классическая задача из набора задач, решаемых на первом курсе. Вот текст этого метода:
public void MultMatr(int[,]A, int[,]B, int[,]C) { if (A.GetLength(1) != B.GetLength(0)) Console.WriteLine("MultMatr: ошибка размерности!"); else for(int i = 0; i < A.GetLength(0); i++) for(int j = 0; j < B.GetLength(1); j++) { int s=0; for(int k = 0; k < A.GetLength(1); k++) s+= A[i,k]*B[k,j]; C[i,j] = s; } }//MultMatr
В особых комментариях эта процедура не нуждается. Замечу лишь, что прежде чем проводить вычисления, производится проверка корректности размерностей исходных матриц при их перемножении, - число столбцов первой матрицы должно быть равно числу строк второй матрицы.
Обратите внимание, как выглядят результаты консольного вывода на данном этапе работы (рис. 11.2).
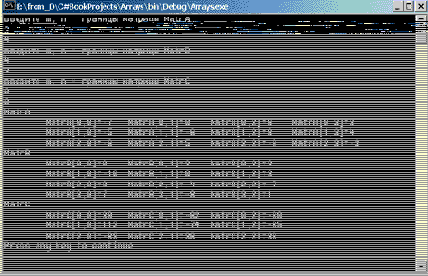
Рис. 11.2. Умножение матриц
Модальные и немодальные формы
Первичным является понятие модального и немодального окна. Окно называется модальным, если нельзя закончить работу в открытом окне до тех пор, пока оно не будет закрыто. Модальное окно не позволяет, если оно открыто, временно переключиться на работу с другим окном. Выйти из модального окна можно, только закрыв его. Немодальные окна допускают параллельную работу в окнах. Форма называется модальной или немодальной в зависимости от того, каково ее окно. Метод Show открывает форму как немодальную, а метод ShowDialog - как модальную. Название метода отражает основное назначение модальных форм - они предназначены для организации диалога с пользователем, и пока диалог не завершится, покидать форму не разрешается.
Модульность
Число классов библиотеки FCL велико (несколько тысяч). Поэтому понадобился способ их структуризации. Логически классы с близкой функциональностью объединяются в группы, называемые пространством имен (Namespace). Для динамического компонента CLR физической единицей, объединяющей классы и другие ресурсы, является сборка (assembly).
Основным пространством имен библиотеки FCL является пространство System, содержащее как классы, так и другие вложенные пространства имен. Так, уже упоминавшийся примитивный тип Int32 непосредственно вложен в пространство имен System и его полное имя, включающее имя пространства - System.Int32.
В пространство System вложен целый ряд других пространств имен. Например, в пространстве System.Collections находятся классы и интерфейсы, поддерживающие работу с коллекциями объектов - списками, очередями, словарями. В пространство System.Collections, в свою очередь, вложено пространство имен Specialized, содержащие классы со специализацией, например, коллекции, элементами которых являются только строки. Пространство System.Windows.Forms содержит классы, используемые при создании Windows-приложений. Класс Form из этого пространства задает форму - окно, заполняемое элементами управления, графикой, обеспечивающее интерактивное взаимодействие с пользователем.
По ходу курса мы будем знакомиться со многими классами, принадлежащими различным пространствам имен библиотеки FCL.
Начало начал - точка "большого взрыва"
Основной операцией, инициирующей вычисления в объектно-ориентированных приложениях, является вызов метода F некоторого класса x, имеющий вид:
x.F(arg1, arg2, ..., argN);
В этом вызове x называется целью вызова, и здесь возможны три ситуации:
x - имя класса. В этом случае метод F должен быть статическим методом класса, объявленным с атрибутом static, как это имеет место, например, для точки вызова - процедуры Main;x - имя объекта или объектное выражение. В этом случае F должен быть обычным, не статическим методом. Иногда такой метод называют экземплярным, подчеркивая тот факт, что метод вызывается экземпляром класса - некоторым объектом;x - не указывается при вызове. Такой вызов называется неквалифицированным, в отличие от двух первых случаев. Заметьте, неквалифицированный вызов вовсе не означает, что цель вызова отсутствует, - она просто задана по умолчанию. Целью является текущий объект (текущий класс для статических методов). Текущий объект имеет зарезервированное имя this. Применяя это имя, любой неквалифицированный вызов можно превратить в квалифицированный вызов. Иногда без этого имени просто не обойтись.
Но как появляются объекты? Как они становятся текущими? Как реализуется самый первый вызов метода, другими словами, кто и где вызывает точку входа - метод Main? С чего все начинается?
Когда CLR получает сборку для выполнения, то в решении, входящем в сборку, отмечен стартовый проект, содержащий класс с точкой входа - статическим методом (процедурой) Main. Некоторый объект исполнительной среды CLR и вызывает этот метод, так что первоначальный вызов метода осуществляется извне приложения. Это и есть точка "большого взрыва" - начало зарождения мира объектов и объектных вычислений. Дальнейший сценарий зависит от содержимого точки входа. Как правило, в ней создаются один или несколько объектов, а затем вызываются методы и/или обработчики событий, происходящих с созданными объектами. В этих методах и обработчиках событий могут создаваться новые объекты, вызываться новые методы и новые обработчики. Так, начиная с одной точки, разворачивается целый мир объектов приложения.
Наследование
Мощь ООП основана на наследовании. Когда построен полезный класс, то он может многократно использоваться. Повторное использование - это одна из главных целей ООП. Но и для хороших классов неизбежно наступает момент, когда необходимо расширить возможности класса, придать ему новую функциональность, изменить интерфейс. Всякая попытка изменять сам работающий класс чревата большими неприятностями - могут перестать работать прекрасно работавшие программы, многим клиентам класса вовсе не нужен новый интерфейс и новые возможности. Здесь-то и приходит на выручку наследование. Существующий класс не меняется, но создается его потомок, продолжающий дело отца, только уже на новом уровне.
Класс-потомок наследует все возможности родительского класса - все поля и все методы, открытую и закрытую часть класса. Правда, не ко всем полям и методам класса возможен прямой доступ потомка. Поля и методы родительского класса, снабженные атрибутом private, хотя и наследуются, но по-прежнему остаются закрытыми, и методы, создаваемые потомком, не могут к ним обращаться напрямую, а только через методы, наследованные от родителя. Единственное, что не наследует потомок - это конструкторы родительского класса. Конструкторы потомок должен создавать сам. В этом есть некоторая разумная идея, и я позже поясню ее суть.
Рассмотрим класс, названный Found, играющий роль родительского класса. У него есть обычные поля, конструкторы и методы, один из которых снабжен новым модификатором virtual, ранее не появлявшимся в классах, другой - модификатором override:
public class Found { //поля protected string name; protected int credit; public Found() { } public Found(string name, int sum) { this.name = name; credit = sum; } public virtual void VirtMethod() { Console.WriteLine ("Отец: " + this.ToString() ); } public override string ToString() { return(String.Format("поля: name = {0}, credit = {1}", name, credit)); } public void NonVirtMethod() { Console.WriteLine ("Мать: " + this.ToString() ); } public void Analysis() { Console.WriteLine ("Простой анализ"); } public void Work() { VirtMethod(); NonVirtMethod(); Analysis(); } }
Заметьте, класс Found, как и все классы, по умолчанию является наследником класса Object, его потомки наследуют методы этого класса уже не напрямую, а через методы родителя, который мог переопределить методы класса Object. В частности, класс Found переопределил метод ToString, задав собственную реализацию возвращаемой методом строки, которая связывается с объектами класса. Как часто делается, в этой строке отображаются значения полей объекта данного класса. На переопределение родительского метода ToString указывает модификатор метода override.
Класс Found закрыл свои поля для клиентов, но открыл для потомков, снабдив их модификатором доступа protected.
Создадим теперь класс Derived - потомка класса Found. В простейшем случае объявление класса может выглядеть так:
public class Derived:Found { }
Тело класса Derived пусто, но это вовсе не значит, что объекты этого класса не имеют полей и методов: они "являются" объектами класса Found, наследуя все его поля и методы (кроме конструктора) и поэтому могут делать все, что могут делать объекты родительского класса.
Вот пример работы с объектами родительского и производного класса:
public void TestFoundDerived() { Found bs = new Found ("father", 777); Console.WriteLine("Объект bs вызывает методы базового класса"); bs.VirtMethod(); bs.NonVirtMethod(); bs.Analysis(); bs.Work(); Derived der = new Derived(); Console.WriteLine("Объект der вызывает методы класса потомка"); der.VirtMethod(); der.NonVirtMethod(); der.Analysis(); der.Work(); }
Результаты работы этой процедуры показаны на рис. 18.2.
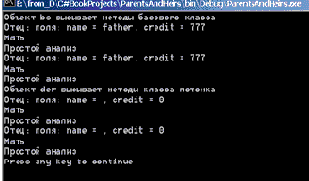
Рис. 18.2. Объект потомка наследует поля и методы родителя
В чем отличие работы объектов bs и der? Поскольку класс-потомок Derived ничего самостоятельно не определял, то он наследовал все поля и методы у своего родителя, за исключением конструкторов. У этого класса имеется собственный конструктор без аргументов, задаваемый по умолчанию. При создании объекта der вызывался его собственный конструктор по умолчанию, инициализирующий поля класса значениями по умолчанию. Об особенностях работы конструкторов потомков скажу чуть позже, сейчас же упомяну лишь, что конструктор по умолчанию потомка вызывает конструктор без аргументов своего родителя, поэтому для успеха работы родитель должен иметь такой конструктор. Заметьте, поскольку родитель не знает, какие у него могут быть потомки, то желательно конструктор без аргументов включать в число конструкторов класса, как это сделано для класса Found.
Наследование форм
Для объектного программиста форма - это обычный класс, а населяющие ее элементы управления - это поля класса. Так что создать новую форму - новый класс, наследующий все поля, методы и события уже существующей формы - не представляет никаких проблем. Достаточно написать, как обычно, одну строку:
public class NewForm : InterfacesAndDrawing.TwoLists
Нужно учитывать, что имени класса родителя должно предшествовать имя пространства имен.
Чаще всего, наследуемые формы создаются в режиме проектирования при выборе пункта меню Add Inherited Form. (Добраться до этого пункта можно двояко. Можно выбрать пункт Project/ AddInheritedForm из главного меню либо выбрать имя проекта в окне проекта и выбрать пункт Add/Add Inherited Form из контекстного меню, открывающегося при щелчке правой кнопкой.)
В результате открывается окно Inheritance Picker, в котором можно выбрать родительскую форму. Заметьте, родительская форма может принадлежать как текущему, так и любому другому проекту. Единственное ограничение - проект, содержащий родительскую форму, должен быть скомпилирован как exe или dll. Вот как выглядит окно для задания родительской формы.
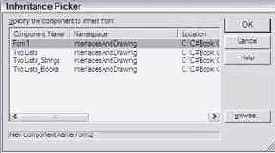
Рис. 24.5. Окно Inheritance Picker наследования форм
При наследовании форм следует обратить внимание на модификаторы доступа элементов управления родительской формы. По умолчанию они имеют статус private, означающий запрет на изменение свойств и обработчиков событий этих элементов. Чаще всего, такая концепция не верна. Мы не можем знать причин, по которым наследникам захочется изменить созданные родителем свойства элементов. Правильным решением является изменение значения модификатора для всех элементов управления родительской формы на protected. У всех элементов родительской формы есть свойство modifiers, в котором можно указать статус элемента управления, что и было сделано для всех элементов нашего шаблона - формы TwoLists.
Наследованную форму можно затем открыть в дизайнере форм, добавить в нее новые элементы и новые обработчики событий или изменить установки наследуемых элементов, если родительская форма предоставила такую возможность. (Хочу предупредить об одном возможном "жучке", связанном с наследованием форм. На одном из моих компьютеров установлена ОС Windows 2000, на другом - Windows XP. Так вот, в Windows 2000 дизайнер отказывается открывать наследуемую форму, хотя она создается и нормально работает. Это происходит как для Visual Studio 2003, так и для beta2 Visual Studio 2005. В Office XP все работает нормально. Не могу утверждать совершенно определенно, что это "жучок", поскольку не проводил тщательного исследования. Но полагаю, что предупредить о такой ситуации полезно.)
Наследование и полиморфизм - альтернатива обратному вызову
Сегодня многие программные системы проектируются и разрабатываются не в функциональном, а в объектно-ориентированном стиле. Такая система представляет собой одно или несколько семейств интерфейсов и классов, связанных отношением наследования. Классы-потомки наследуют методы своих родителей, могут их переопределять и добавлять новые методы. Переопределив метод родителя, потомки без труда могут вызывать как собственный метод, так и метод родителя; все незакрытые методы родителя им известны и доступны. Но может ли родитель вызывать методы, определенные потомком, учитывая, что в момент создания родительского метода потомок не только не создан, но еще, скорее всего, и не спроектирован? Тем не менее, ответ на этот вопрос положителен. Достигается такая возможность опять-таки благодаря контрактам, заключаемым при реализации полиморфизма.
О полиморфизме говорилось достаточно много в предыдущих лекциях. Тем не менее, позволю напомнить суть дела. Родитель может объявить свой метод виртуальным, в этом случае в контракте на метод потомку разрешается переопределить реализацию, но он не имеет права изменять сигнатуру виртуального метода. Когда некоторый метод родителя Q вызывает виртуальный метод F, то, благодаря позднему связыванию, реализуется полиморфизм и реально будет вызван не метод родителя F, а метод F, который реализован потомком, вызвавшим родительский метод Q. Ситуация в точности напоминает раскрутку и вызов обратных функций. Родительский метод Q находится во внутреннем слое, а потомок с его методом F определен во внешнем слое. Когда потомок вызывает метод Q из внутреннего слоя, тот, в свою очередь, вызывает метод F из внешнего слоя. Сигнатура вызываемого метода F в данном случае задается не делегатом, а сигнатурой виртуального метода, которую, согласно контракту, потомок не может изменить. Давайте вернемся к задаче вычисления интеграла и создадим реализацию, основанную на наследовании и полиморфизме.
Идея примера такова. Вначале построим родительский класс, метод которого будет вычислять интеграл от некоторой подынтегральной функции, заданной виртуальным методом класса. Далее построим класс-потомок, наследующий родительский метод вычисления интеграла и переопределяющий виртуальный метод, в котором потомок задаст собственную подынтегральную функцию. При такой технологии, всякий раз, когда нужно вычислить интеграл, нужно создать класс-потомок, в котором переопределяется виртуальный метод. Приведу пример кода, следующего этой схеме:
class FIntegral { //базовый класс, в котором определен метод вычисления //интеграла и виртуальный метод, задющий базовую //подынтегральную функцию public double EvaluateIntegral(double a, double b, double eps) { int n=4; double I0=0, I1 = I( a, b, n); for( n=8; n < Math.Pow(2.0,15.0); n*=2) { I0 =I1; I1=I(a,b,n); if(Math.Abs(I1-I0)<eps)break; } if(Math.Abs(I1-I0)< eps) Console.WriteLine("Требуемая точность достигнута! "+ " eps = {0}, достигнутая точность ={1}, n= {2}", eps,Math.Abs(I1-I0),n); else Console.WriteLine("Требуемая точность не достигнута! "+ " eps = {0}, достигнутая точность ={1}, n= {2}", eps,Math.Abs(I1-I0),n); return(I1); } private double I(double a, double b, int n) { //Вычисляет частную сумму по методу трапеций double x = a, sum = sif(x)/2, dx = (b-a)/n; for (int i= 2; i <= n; i++) { x += dx; sum += sif(x); } x = b; sum += sif(x)/2; return(sum*dx); } protected virtual double sif(double x) {return(1.0);}
}//FIntegral
Этот код большей частью знаком. В отличие от класса HighOrderIntegral, здесь нет делегата, у функции EvaluateIntegral нет параметра функционального типа. Вместо этого тут же в классе определен защищенный виртуальный метод, задающий конкретную подынтегральную функцию. В качестве таковой выбрана самая простая функция, тождественно равная единице.
Для вычисления интеграла от реальной функции единственное, что теперь нужно сделать - это задать класс-потомок, переопределяющий виртуальный метод. Вот пример такого класса:
class FIntegralSon:FIntegral { protected override double sif(double x) { double a = 1.0; double b = 2.0; double c= 3.0; return (double)(a*x*x +b*x +c); } }//FIntegralSon
Принципиально задача решена. Осталось только написать фрагмент кода, запускающий вычисления. Он оформлен в виде следующей процедуры:
public void TestPolymorphIntegral() { FIntegral integral1 = new FIntegral(); FIntegralSon integral2 = new FIntegralSon(); double res1 = integral1.EvaluateIntegral(2.0,3.0,0.1e-5); double res2 = integral2.EvaluateIntegral(2.0,3.0,0.1e-5); Console.WriteLine("Father = {0}, Son = {1}", res1,res2); }//PolymorphIntegral
Взгляните на результаты вычислений.

Рис. 20.4. Вычисление интеграла, использующее полиморфизм
Наследование и универсальность
Необходимость в универсализации возникает с первых шагов программирования. Одна из первых процедур, появляющихся при обучении программированию - это процедура свопинга:обмен значениями двух переменных одного типа. Выглядит она примерно так:
public void Swap(ref T x1, ref T x2) { T temp; temp = x1; x1 = x2; x2 = temp; }
Если тип T - это вполне определенный тип, например int, string или Person, то никаких проблем не существует, все совершенно прозрачно. Но как быть, если возникает необходимость обмена данными разного типа? Неужели нужно писать копии этой процедуры для каждого типа? Проблема легко решается в языках, где нет контроля типов - там достаточно иметь единственный экземпляр такой процедуры, прекрасно работающий, но лишь до тех пор, пока передаются аргументы одного типа. Когда же процедуре будут переданы фактические аргументы разного типа, то немедленно возникнет ошибка периода выполнения, и это слишком дорогая плата за универсальность.
В типизированных языках, не обладающих механизмом универсализации, выхода практически нет - приходится писать многочисленные копии Swap.
|
До недавнего времени Framework .Net и соответственно язык C# не поддерживали универсальность. Так что те, кто работает с языком C#, входящим в состав Visual Studio 2003 и ранних версий, должны смириться с отсутствием универсальных классов. Но в новой версии Visual Studio 2005, носящей кодовое имя Whidbey, проблема решена, и программисты получили наконец долгожданный механизм универсальности. Я использую в примерах этой лекции бета-версию Whidbey. Замечу, что хотя меня прежде всего интересовала реализация универсальности, но и общее впечатление от Whidbey самое благоприятное. |
Для достижения универсальности процедуры Swap следует рассматривать тип T как ее параметр, такой же, как и сами аргументы x1 и x2. Суть универсальности в том, чтобы в момент вызова процедуры передавать ей не только фактические аргументы, но и их фактический тип.
Под универсальностью (genericity) понимается способность класса объявлять используемые им типы как параметры. Класс с параметрами, задающими типы, называется универсальным классом (generic class). Терминология не устоялась и синонимами термина "универсальный класс" являются термины: родовой класс, параметризованный класс, класс с родовыми параметрами. В языке С++ универсальные классы называются шаблонами (template).
Наследование от общего предка
Проблема наследования от общего предка характерна, в первую очередь, для множественного наследования классов. Если класс C является наследником классов A и B, а те, в свой черед, являются наследниками класса Parent, то класс наследует свойства и методы своего предка Parent дважды, один раз получая их от класса A, другой от - B. Это явление называется еще дублирующим наследованием. Для классов ситуация осложняется тем, что классы A и B могли по-разному переопределить методы родителя и для потомков предстоит сложный выбор реализации.
Для интерфейсов сама ситуация дублирующего наследования маловероятна, но возможна, поскольку интерфейс, как и любой класс, может быть наследником другого интерфейса. Поскольку у интерфейсов наследуются только сигнатуры, а не реализации, как в случае классов, то проблема дублирующего наследования сводится к проблеме коллизии имен. По-видимому, естественным решением этой проблемы в данной ситуации является склеивание, когда методам, пришедшим разными путями от одного родителя, будет соответствовать единая реализация.
Начнем наш пример с наследования интерфейсов:
public interface IParent { void ParentMethod(); } public interface ISon1:IParent { void Son1Method(); } public interface ISon2:IParent { void Son2Method(); }
Два сыновних интерфейса наследуют метод своего родителя. А теперь рассмотрим класс, наследующий оба интерфейса:
public class Pars:ISon1, ISon2 { public void ParentMethod() { Console.WriteLine("Это метод родителя!"); } public void Son1Method() { Console.WriteLine("Это метод старшего сына!"); } public void Son2Method() { Console.WriteLine("Это метод младшего сына!"); } }//class Pars
Класс обязан реализовать метод ParentMethod, приходящий от обоих интерфейсов. Понимая, что речь идет о дублировании метода общего родителя - интерфейса IParent, лучшей стратегией реализации является склеивание методов в одной реализации, что и было сделано. Приведу тестирующую процедуру, где создается объект класса и три объекта интерфейсных классов, каждый из которых может вызывать только методы своего интерфейса:
public void TestIParsons() { Console.WriteLine("Объект класса вызывает методы трех интерфейсов!"); Cli.Pars ct = new Cli.Pars(); ct.ParentMethod(); ct.Son1Method(); ct.Son2Method(); Console.WriteLine("Интерфейсный объект 1 вызывает свои методы!"); Cli.IParent ip = (IParent)ct; ip.ParentMethod(); Console.WriteLine("Интерфейсный объект 2 вызывает свои методы!"); Cli.ISon1 ip1 = (ISon1)ct; ip1.ParentMethod(); ip1.Son1Method(); Console.WriteLine("Интерфейсный объект 3 вызывает свои методы!"); Cli.ISon2 ip2 = (ISon2)ct; ip2.ParentMethod(); ip2.Son2Method(); }
Результаты работы тестирующей процедуры показаны на рис. 19.3.
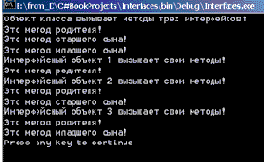
Рис. 19.3. Дублирующее наследование интерфейсов
Неизменяемый класс string
В языке C# существует понятие неизменяемый (immutable) класс. Для такого класса невозможно изменить значение объекта при вызове его методов. Динамические методы могут создавать новый объект, но не могут изменить значение существующего объекта.
К таким неизменяемым классам относится и класс String. Ни один из методов этого класса не меняет значения существующих объектов. Конечно, некоторые из методов создают новые значения и возвращают в качестве результата новые строки. Невозможность изменять значения строк касается не только методов. Аналогично, при работе со строкой как с массивом разрешено только чтение отдельных символов, но не их замена. Оператор присваивания из нашего последнего примера, в котором делается попытка изменить первый символ строки, недопустим, а потому закомментирован.
//Неизменяемые значения s1= "Zenon"; ch1 = s1[0]; //s1[0]='L';
Немного теории
Пусть T = {a1, a2, ....an} - алфавит символов. Словом в алфавите T называется последовательность записанных подряд символов, а длиной слова - число его символов. Пустое слово, не содержащее символов, обычно обозначается как e. Алфавит T можно рассматривать как множество всех слов длины 1. Рассмотрим операцию конкатенации над множествами, так, что конкатенация алфавита T с самим собой дает множество всех слов длины 2. Обозначается конкатенация ТТ как Т2. Множество всех слов длины k обозначается - Tk, его можно рассматривать как k-кратную конкатенацию алфавита T. Множество всех непустых слов произвольной длины, полученное объединением всех множеств Tk, обозначается T+, а объединение этого множества с пустым словом называется итерацией языка и обозначается T*. Итерация описывает все возможные слова, которые можно построить в данном алфавите. Любое подмножество слов L(T), содержащееся в T*, называется языком в алфавите T.
Определим класс языков, задаваемых регулярными множествами. Регулярное множество определяется рекурсивно следующими правилами:
пустое множество, а также множество, содержащее пустое слово, и одноэлементные множества, содержащие символы алфавита, являются регулярными базисными множествами;если множества P и Q являются регулярными, то множества, построенные применением операций объединения, конкатенации и итерации - P>>Q, PQ, P*, Q* - тоже являются регулярными.
Регулярные выражения представляют удобный способ задания регулярных множеств. Аналогично множествам, они определяются рекурсивно:
регулярные базисные выражения задаются символами и определяют соответствующие регулярные базисные множества, например, выражение f задает одноэлементное множество {f} при условии, что f - символ алфавита T;если p и q - регулярные выражения, то операции объединения, конкатенации и итерации - p+q, pq, p*, q* - являются регулярными выражениями, определяющими соответствующие регулярные множества.
По сути, регулярные выражения - это более простой и удобный способ записи регулярных множеств в виде обычной строки. Каждое регулярное множество, а, следовательно, и каждое регулярное выражение задает некоторый язык L(T) в алфавите T. Этот класс языков - достаточно мощный, с его помощью можно описать интересные языки, но устроены они довольно просто - их можно определить также с помощью простых грамматик, например, правосторонних грамматик. Более важно, что для любого регулярного выражения можно построить конечный автомат, который распознает, принадлежит ли заданное слово языку, порожденному регулярным выражением. На этом основана практическая ценность регулярных выражений.
С точки зрения практика регулярное выражение задает образец поиска. После чего можно проверить, удовлетворяет ли заданная строка или ее подстрока данному образцу. В языках программирования синтаксис регулярного выражения существенно обогащается, что дает возможность более просто задавать сложные образцы поиска. Такие синтаксические надстройки, хотя и не меняют сути регулярных выражений, крайне полезны для практиков, избавляя программиста от ненужных сложностей. (В Net Framework эти усложнения, на мой взгляд, чрезмерны. Выигрывая в мощности языка, проигрываем в простоте записи его выражений.)
О соответствии списков формальных и фактических аргументов
Между списком формальных и списком фактических аргументов должно выполняться определенное соответствие по числу, порядку следования, типу и статусу аргументов. Если в первом списке n формальных аргументов, то фактических аргументов должно быть не меньше n (соответствие по числу). Каждому i-му формальному аргументу (для всех i от 1 до n-1) ставится в соответствие i-й фактический аргумент. Последнему формальному аргументу, при условии, что он объявлен с ключевым словом params, ставятся в соответствие все оставшиеся фактические аргументы (соответствие по порядку). Если формальный аргумент объявлен с ключевым словом ref или out, то фактический аргумент должен сопровождаться таким же ключевым словом в точке вызова (соответствие по статусу).
|
Появление ключевых слов при вызове методов - это особенность языка C#, отличающая его от большинства других языков. Такой синтаксис следует приветствовать, поскольку он направлен на повышение надежности программной системы, напоминая программисту о том, что данный фактический аргумент является выходным и значение его наверняка изменится после вызова метода. Однако из-за непривычности синтаксиса при вызове методов эти слова часто забывают писать, что приводит к появлению синтаксических ошибок. |
Если формальный аргумент объявлен с типом T, то выражение, задающее фактический аргумент, должно быть согласовано по типу с типом T: допускает преобразование к типу T, совпадает c типом T или является его потомком (соответствие по типу).
Если формальный аргумент является выходным - объявлен с ключевым словом ref или out, - то соответствующий фактический аргумент не может быть выражением, поскольку используется в левой части оператора присваивания; следовательно, он должен быть именем, которому можно присвоить значение.
Объявление массивов
Рассмотрим, как объявляются одномерные массивы, массивы массивов и многомерные массивы.
Объявление одномерных массивов
Напомню общую структуру объявления:
[<атрибуты>] [<модификаторы>] <тип> <объявители>;
Забудем пока об атрибутах и модификаторах. Объявление одномерного массива выглядит следующим образом:
<тип>[] <объявители>;
Заметьте, в отличие от языка C++ квадратные скобки приписаны не к имени переменной, а к типу. Они являются неотъемлемой частью определения класса, так что запись T[] следует понимать как класс одномерный массив с элементами типа T.
Что же касается границ изменения индексов, то эта характеристика к классу не относится, она является характеристикой переменных - экземпляров, каждый из которых является одномерным массивом со своим числом элементов, задаваемых в объявителе переменной.
Как и в случае объявления простых переменных, каждый объявитель может быть именем или именем с инициализацией. В первом случае речь идет об отложенной инициализации. Нужно понимать, что при объявлении с отложенной инициализацией сам массив не формируется, а создается только ссылка на массив, имеющая неопределенное значение Null. Поэтому пока массив не будет реально создан и его элементы инициализированы, использовать его в вычислениях нельзя. Вот пример объявления трех массивов с отложенной инициализацией:
int[] a, b, c;
Чаще всего при объявлении массива используется имя с инициализацией. И опять-таки, как и в случае простых переменных, могут быть два варианта инициализации. В первом случае инициализация является явной и задается константным массивом. Вот пример:
double[] x= {5.5, 6.6, 7.7};
Следуя синтаксису, элементы константного массива следует заключать в фигурные скобки.
Во втором случае создание и инициализация массива выполняется в объектном стиле с вызовом конструктора массива. И это наиболее распространенная практика объявления массивов. Приведу пример:
int[] d= new int[5];
Итак, если массив объявляется без инициализации, то создается только висячая ссылка со значением void. Если инициализация выполняется конструктором, то в динамической памяти создается сам массив, элементы которого инициализируются константами соответствующего типа (ноль для арифметики, пустая строка для строковых массивов), и ссылка связывается с этим массивом. Если массив инициализируется константным массивом, то в памяти создается константный массив, с которым и связывается ссылка.
Как обычно задаются элементы массива, если они не заданы при инициализации? Они либо вычисляются, либо вводятся пользователем. Давайте рассмотрим первый пример работы с массивами из проекта с именем Arrays, поддерживающего эту лекцию:
public void TestDeclaration() { //объявляются три одномерных массива A,B,C int[] A = new int[5], B= new int[5], C= new int[5]; Arrs.CreateOneDimAr(A); Arrs.CreateOneDimAr(B); for(int i = 0; i<5; i++) C[i] = A[i] + B[i]; //объявление массива с явной инициализацией int[] x ={5,5,6,6,7,7}; //объявление массивов с отложенной инициализацией int[] u,v; u = new int[3]; for(int i=0; i<3; i++) u[i] =i+1; //v= {1,2,3}; //присваивание константного массива //недопустимо v = new int[4]; v=u; //допустимое присваивание int [,] w = new int[3,5]; //v=w; //недопустимое присваивание: объекты разных классов Arrs.PrintAr1("A", A); Arrs.PrintAr1("B", B); Arrs.PrintAr1("C", C); Arrs.PrintAr1("X", x); Arrs.PrintAr1("U", u); Arrs.PrintAr1("V", v); }
На что следует обратить внимание, анализируя этот текст:
В процедуре показаны разные способы объявления массивов. Вначале объявляются одномерные массивы A, B и C, создаваемые конструктором. Значения элементов этих трех массивов имеют один и тот же тип int. То, что они имеют одинаковое число элементов, произошло по воле программиста, а не диктовалось требованиями языка. Заметьте, что после такого объявления с инициализацией конструктором, все элементы имеют значение, в данном случае - ноль, и могут участвовать в вычислениях.Массив x объявлен с явной инициализацией. Число и значения его элементов определяется константным массивом.Массивы u и v объявлены с отложенной инициализацией. В последующих операторах массив u инициализируется в объектном стиле - элементы получают его в цикле значения.Обратите внимание на закомментированный оператор присваивания. В отличие от инициализации, использовать константный массив в правой части оператора присваивания недопустимо. Эта попытка приводит к ошибке, поскольку v - это ссылка, которой можно присвоить ссылку, но нельзя присвоить константный массив. Ссылку присвоить можно. Что происходит в операторе присваивания v = u? Это корректное ссылочное присваивание: хотя u и v имеют разное число элементов, но они являются объектами одного класса. В результате присваивания память, отведенная массиву v, освободится, ею займется теперь сборщик мусора. Обе ссылки u и v будут теперь указывать на один и тот же массив, так что изменение элемента одного массива немедленно отразится на другом массиве.Далее определяется двумерный массив w и делается попытка выполнить оператор присваивания v=w. Это ссылочное присваивание некорректно, поскольку объекты w и v - разных классов и для них не выполняется требуемое для присваивания согласование по типу.Для поддержки работы с массивами создан специальный класс Arrs, статические методы которого выполняют различные операции над массивами. В частности, в примере использованы два метода этого класса, один из которых заполняет массив случайными числами, второй - выводит массив на печать. Вот текст первого из этих методов:public static void CreateOneDimAr(int[] A) { for(int i = 0; i<A.GetLength(0);i++) A[i] = rnd.Next(1,100); }//CreateOneDimAr
Здесь rnd - это статическое поле класса Arrs, объявленное следующим образом:
private static Random rnd = new Random();
Процедура печати массива с именем name выглядит так:
public static void PrintAr1(string name,int[] A) { Console.WriteLine(name); for(int i = 0; i<A.GetLength(0);i++) Console.Write("\t" + name + "[{0}]={1}", i, A[i]); Console.WriteLine(); }//PrintAr1
На рис. 11.1 показан консольный вывод результатов работы процедуры TestDeclarations.
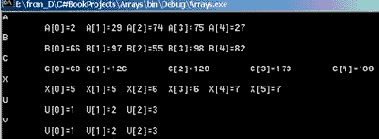
Рис. 11.1. Результаты объявления и создания массивов
Особое внимание обратите на вывод, связанный с массивами u и v.
Объявление переменных
В лекции 4 рассматривались типы языка C#. Естественным продолжением этой темы является рассмотрение переменных языка. Переменные и типы - тесно связанные понятия. С объектной точки зрения переменная - это экземпляр типа. Скалярную переменную можно рассматривать как сущность, обладающую именем, значением и типом. Имя и тип задаются при объявлении переменной и остаются неизменными на все время ее жизни. Значение переменной может меняться в ходе вычислений, эта возможность вариации значений и дало имя понятию переменная (Variable) в математике и программировании. Получение начального значения переменной называется ее инициализацией. Важной новинкой языка C# является требование обязательной инициализации переменной до начала ее использования. Попытка использовать неинициализированную переменную приводит к ошибкам, обнаруживаемым еще на этапе компиляции. Инициализация переменных, как правило, выполняется в момент объявления, хотя и может быть отложена.
Тесная связь типов и классов в языке C# обсуждалась в предыдущей лекции. Не менее тесная связь существует между переменными и объектами. Так что, когда речь идет о переменной значимого типа, то во многих ситуациях она может играть роль объекта некоторого класса. В этой лекции обсуждение будет связано со скалярными переменными встроенных типов. Все переменные, прежде чем появиться в вычислениях, должны быть объявлены. Давайте рассмотрим, как это делается в C#.
Объявление строк. Конструкторы класса string
Объекты класса String объявляются как все прочие объекты простых типов - с явной или отложенной инициализацией, с явным или неявным вызовом конструктора класса. Чаще всего, при объявлении строковой переменной конструктор явно не вызывается, а инициализация задается строковой константой. Но у класса String достаточно много конструкторов. Они позволяют сконструировать строку из:
символа, повторенного заданное число раз;массива символов char[];части массива символов.
Некоторым конструкторам в качестве параметра инициализации можно передать строку, заданную типом char*. Но все это небезопасно, и подобные примеры приводиться и обсуждаться не будут. Приведу примеры объявления строк с вызовом разных конструкторов:
public void TestDeclStrings() { //конструкторы string world = "Мир"; //string s1 = new string("s1"); //string s2 = new string(); string sssss = new string('s',5); char[] yes = "Yes".ToCharArray(); string stryes = new string(yes); string strye = new string(yes,0,2); Console.WriteLine("world = {0}; sssss={1}; stryes={2};"+ " strye= {3}", world, sssss, stryes, strye); }
Объект world создан без явного вызова конструктора, а объекты sssss, stryes, strye созданы разными конструкторами класса String.
Заметьте, не допускается явный вызов конструктора по умолчанию - конструктора без параметров. Нет также конструктора, которому в качестве аргумента можно передать обычную строковую константу. Соответствующие операторы в тексте закомментированы.
Объявление строк. Конструкторы класса StringBuilder
Объекты этого класса объявляются с явным вызовом конструктора класса. Поскольку специальных констант этого типа не существует, то вызов конструктора для инициализации объекта просто необходим. Конструктор класса перегружен, и наряду с конструктором без параметров, создающим пустую строку, имеется набор конструкторов, которым можно передать две группы параметров. Первая группа позволяет задать строку или подстроку, значением которой будет инициализироваться создаваемый объект класса StringBuilder. Вторая группа параметров позволяет задать емкость объекта - объем памяти, отводимой данному экземпляру класса StringBuilder. Каждая из этих групп не является обязательной и может быть опущена. Примером может служить конструктор без параметров, который создает объект, инициализированный пустой строкой, и с некоторой емкостью , заданной по умолчанию, значение которой зависит от реализации. Приведу в качестве примера синтаксис трех конструкторов:
public StringBuilder (string str, int cap). Параметр str задает строку инициализации, cap - емкость объекта;public StringBuilder (int curcap, int maxcap). Параметры curcap и maxcap задают начальную и максимальную емкость объекта;public StringBuilder (string str, int start, int len, int cap). Параметры str, start, len задают строку инициализации, cap - емкость объекта.
Обработка исключений в языках C/C++
Для стиля программирования на языке C характерно описание методов класса как булевых функций, возвращающих true в случае нормального завершения метода и false - при возникновении исключительной ситуации. Вызов метода встраивался в If-оператор, обрабатывающий ошибку в случае неуспеха завершения метода:
bool MyMethod(...){...} if !MyMethod(){// обработка ошибки} {//нормальное выполнение}
Недостатки этой схемы понятны. Во-первых, мало информации о причине возникновения ошибки, поэтому либо через поля класса, либо через аргументы метода нужно передавать дополнительную информацию. Во-вторых, блок обработки встраивается в каждый вызов, что приводит к раздуванию кода.
Поэтому в C/C++ применяется схема try/catch блоков, суть которой в следующем. Участок программы, в котором может возникнуть исключительная ситуация, оформляется в виде охраняемого try-блока. Если при его выполнении возникает исключительная ситуация, то происходит прерывание выполнения try-блока c классификацией исключения. Это исключение начинает обрабатывать один из catch-блоков, соответствующий типу исключения. В C/C++ применяются две такие схемы. Одна из них - схема с возобновлением - соответствует так называемым структурным, или С-исключениям. Вторая схема - без возобновления - соответствует С++ исключениям. В первой схеме обработчик исключения - catch-блок - возвращает управление в некоторую точку try-блока. Во второй схеме управление не возвращается в try-блок.
С некоторыми синтаксическими отличиями схема с возобновлением применяется в языках VB/VBA.
|
Многообразие подходов к обработке исключений говорит о том, что не найден единый, удовлетворяющий всех подход. Чуть позже я расскажу о наиболее разумной, с моей точки зрения, схеме. К сожалению, в C# применяется не она. |
Обработка исключительных ситуаций
Какой бы надежный код ни был написан, сколь бы тщательной ни была отладка, в версии, переданной в эксплуатацию и на сопровождение, при запусках будут встречаться нарушения спецификаций. Причиной этого являются выше упомянутые законы программотехники. В системе остается последняя ошибка, находятся пользователи, не знающие спецификаций, и если спецификацию можно нарушить, то это событие когда-нибудь да произойдет. В таких исключительных ситуациях продолжение выполнения программы либо становится невозможным (попытка выполнить неразрешенную операцию деления на ноль, попытки записи в защищенную область памяти, попытка открытия несуществующего файла, попытка получить несуществующую запись базы данных), либо в возникшей ситуации применение алгоритма приведет к ошибочным результатам.
Что делать при возникновении исключительной ситуации? Конечно, всегда есть стандартный способ - сообщить о возникшей ошибке и прервать выполнение программы. Понятно, что это приемлемо лишь для безобидных приложений; даже для компьютерных игр этот способ не годится, что уж говорить о критически важных приложениях!
В языках программирования для обработки исключительных ситуаций предлагались самые разные подходы.
Образцы форм
Создание элегантного, интуитивно ясного интерфейса пользователя - это своего рода искусство, требующее определенного художественного вкуса. Здесь все играет важную роль: размеры и расположение элементов управления, шрифты, важную роль играет цвет. Но тема красивого интерфейса лежит вне нашего рассмотрения. Нас сейчас волнует содержание. Полезно знать некоторые образцы организации интерфейса.
Общеязыковая исполнительная среда CLR - динамический компонент каркаса
Наиболее революционным изобретением Framework .Net явилось создание исполнительной среды CLR. С ее появлением процесс написания и выполнения приложений становится принципиально другим. Но обо всем по порядку.
Общие спецификации и совместимые модули
Уже говорилось, что каркас Framework .Net облегчает межъязыковое взаимодействие. Для того чтобы классы, разработанные на разных языках, мирно уживались в рамках одного приложения, для их бесшовной отладки и возможности построения разноязычных потомков они должны удовлетворять некоторым ограничениям. Эти ограничения задаются набором общеязыковых спецификаций - CLS (Common Language Specification). Класс, удовлетворяющий спецификациям CLS, называется CLS-совместимым. Он доступен для использования в других языках, классы которых могут быть клиентами или наследниками совместимого класса.
Спецификации CLS точно определяют, каким набором встроенных типов можно пользоваться в совместимых модулях. Понятно, что эти типы должны быть общедоступными для всех языков, использующих Framework .Net. В совместимых модулях должны использоваться управляемые данные и выполняться некоторые другие ограничения. Заметьте, ограничения касаются только интерфейсной части класса, его открытых свойств и методов. Закрытая часть класса может и не удовлетворять CLS. Классы, от которых не требуется совместимость, могут использовать специфические особенности языка программирования.
На этом я закончу обзорное рассмотрение Visual Studio .Net и ее каркаса Framework .Net. Одной из лучших книг, подробно освещающих эту тему, является книга Джеффри Рихтера, переведенная на русский язык: "Программирование на платформе .Net Framework". Крайне интересно, что для Рихтера языки являются лишь надстройкой над каркасом, поэтому он говорит о программировании, использующем возможности исполнительной среды CLR и библиотеки FCL.
Общий взгляд
Знакомство с новым языком программирования разумно начинать с изучения системы типов этого языка. Как в нем устроена система типов данных? Какие есть простые типы, как создаются сложные, структурные типы, как определяются собственные типы, динамические типы, как определяются классы?
В первых языках программирования понятие класса отсутствовало - рассматривались только типы данных. При определении типа явно задавалось только множество возможных значений, которые могут принимать переменные этого типа. Например, тип integer задает целые числа в некотором диапазоне. Неявно с типом всегда связывался и набор разрешенных операций. В типизированных языках, к которым относится большинство языков программирования, понятие переменной естественным образом связывалось с типом. Если есть тип Т и переменная x типа Т, то это означало, что переменная может принимать значения из множества, заданного типом, и к ней применимы операции, разрешенные типом.
Классы и объекты впервые появились в программировании в языке Симула 67. Произошло это спустя 10 лет после появления первого алгоритмического языка Фортран. Определение класса наряду с описанием данных содержало четкое определение операций или методов, применимых к данным. Объекты - экземпляры класса являются обобщением понятия переменной. Сегодня определение класса в C# и других объектных языках, аналогично определению типа в CTS, содержит:
данные, задающие свойства объектов класса;методы, определяющие поведение объектов класса;события, которые могут происходить с объектами класса.
Так есть ли различие между этими двумя основополагающими понятиями - типом и классом? На первых порах можно считать, что класс - это хорошо определенный тип данных, объект - хорошо определенная переменная. Понятия фактически являются синонимами, какое из них употреблять лишь дело вкуса. Встроенные типы, такие как integer или string, предпочитают называть по-прежнему типами, а их экземпляры - переменными. Что же касается абстракции данных, описывающей служащих и названной, например, Employee, то естественнее называть ее классом, а ее экземпляры - объектами. Такой взгляд на типы и классы довольно полезен, но он не является полным. Позже при обсуждении классов и наследования постараемся более четко определить принципиальные различия в этих понятиях.
Объектно-ориентированное программирование, доминирующее сегодня, построено на классах и объектах. Тем не менее, понятия типа и переменной все еще остаются центральными при описании языков программирования, что характерно и для языка C#. Заметьте, что и в Framework .Net предпочитают говорить о системе типов, хотя все типы библиотеки FCL являются классами.
Типы данных принято разделять на простые и сложные в зависимости от того, как устроены их данные. У простых (скалярных) типов возможные значения данных едины и неделимы. Сложные типы характеризуются способом структуризации данных - одно значение сложного типа состоит из множества значений данных, организующих сложный тип.
Есть и другие критерии классификации типов. Так, типы разделяются на встроенные типы и типы, определенные программистом (пользователем). Встроенные типы изначально принадлежат языку программирования и составляют его базис. В основе системы типов любого языка программирования всегда лежит базисная система типов, встроенных в язык. На их основе программист может строить собственные, им самим определенные типы данных. Но способы (правила) создания таких типов являются базисными, встроенными в язык.
Типы данных разделяются также на статические и динамические. Для данных статического типа память отводится в момент объявления, требуемый размер данных (памяти) известен при их объявлении. Для данных динамического типа размер данных в момент объявления обычно неизвестен и память им выделяется динамически по запросу в процессе выполнения программы.
Еще одна важная классификация типов - это их деление на значимые и ссылочные. Для значимых типов значение переменной (объекта) является неотъемлемой собственностью переменной (точнее, собственностью является память, отводимая значению, а само значение может изменяться). Для ссылочных типов значением служит ссылка на некоторый объект в памяти, расположенный обычно в динамической памяти - "куче". Объект, на который указывает ссылка, может быть разделяемым. Это означает, что несколько ссылочных переменных могут указывать на один и тот же объект и разделять его значения. Значимый тип принято называть развернутым, подчеркивая тем самым, что значение объекта развернуто непосредственно в памяти, отводимой объекту. О ссылочных и значимых типах еще предстоит обстоятельный разговор.
Для большинства процедурных языков, реально используемых программистами - Паскаль, C++, Java, Visual Basic, C#, - система встроенных типов более или менее одинакова. Всегда в языке присутствуют арифметический, логический (булев), символьный типы. Арифметический тип всегда разбивается на подтипы. Всегда допускается организация данных в виде массивов и записей (структур). Внутри арифметического типа всегда допускаются преобразования, всегда есть функции, преобразующие строку в число и обратно. Так что, мой читатель, Ваше знание, по крайней мере, одного из процедурных языков позволяет построить общую картину системы типов и для языка C#. Отличия будут в нюансах, которые и придают аромат и неповторимость языку.
Поскольку язык C# является непосредственным потомком языка C++, то и системы типов этих двух языков близки и совпадают вплоть до названия типов и областей их определения. Но отличия, в том числе принципиального характера, есть и здесь.
Общий взгляд
Массив задает способ организации данных. Массивом называют упорядоченную совокупность элементов одного типа. Каждый элемент массива имеет индексы, определяющие порядок элементов. Число индексов характеризует размерность массива. Каждый индекс изменяется в некотором диапазоне [a,b]. В языке C#, как и во многих других языках, индексы задаются целочисленным типом. В других языках, например, в языке Паскаль, индексы могут принадлежать счетному конечному множеству, на котором определены функции, задающие следующий и предыдущий элемент. Диапазон [a,b] называется граничной парой, a - нижней границей, b - верхней границей индекса. При объявлении массива границы задаются выражениями. Если все границы заданы константными выражениями, то число элементов массива известно в момент его объявления и ему может быть выделена память еще на этапе трансляции. Такие массивы называются статическими. Если же выражения, задающие границы, зависят от переменных, то такие массивы называются динамическими, поскольку память им может быть отведена только динамически в процессе выполнения программы, когда становятся известными значения соответствующих переменных. Массиву, как правило, выделяется непрерывная область памяти.
| В языке C++ все массивы являются статическими; более того, все массивы являются 0-базируемыми. Это означает, что нижняя граница всех индексов массива фиксирована и равна нулю. Введение такого ограничения имеет свою логику, поскольку здесь широко используется адресная арифметика. Так, несколько странное выражение mas + i , где mas - это имя массива, а i - индексное выражение, имеет вполне определенный смысл для C++ программистов. Имя массива интерпретируется как адрес первого элемента массива, к этому адресу прибавляется число, равное произведению i на размер памяти, необходимой для одного элемента массива. В результате сложения в такой адресной арифметике эффективно вычисляется адрес элемента mas[i]. |
В языке C# снято существенное ограничение языка C++ на статичность массивов. Массивы в языке C# являются настоящими динамическими массивами. Как следствие этого, напомню, массивы относятся к ссылочным типам, память им отводится динамически в "куче". К сожалению, не снято ограничение 0-базируемости, хотя, на мой взгляд, в таком ограничении уже нет логики из-за отсутствия в C# адресной арифметики. Было бы гораздо удобнее во многих задачах иметь возможность работать с массивами, у которых нижняя граница не равна нулю.
| В языке C++ "классических" многомерных массивов нет. Здесь введены одномерные массивы и массивы массивов. Последние являются более общей структурой данных и позволяют задать не только многомерный куб, но и изрезанную, ступенчатую структуру. Однако использование массива массивов менее удобно, и, например, классик и автор языка C++ Бьерн Страуструп в своей книге "Основы языка C++" пишет: "Встроенные массивы являются главным источником ошибок - особенно когда они используются для построения многомерных массивов. Для новичков они также являются главным источником смущения и непонимания. По возможности пользуйтесь шаблонами vector, valarray и т.п.".
Шаблоны, определенные в стандартных библиотеках, конечно, стоит использовать, но все-таки странной является рекомендация не пользоваться структурами, встроенными непосредственно в язык. Замечу, что в других языках массивы являются одной из любимых структур данных, используемых программистами. |
В языке C#, соблюдая преемственность, сохранены одномерные массивы и массивы массивов. В дополнение к ним в язык добавлены многомерные массивы. Динамические многомерные массивы языка C# являются весьма мощной, надежной, понятной и удобной структурой данных, которую смело можно рекомендовать к применению не только профессионалам, но и новичкам, программирующим на C#. После этого краткого обзора давайте перейдем к более систематическому изучению деталей работы с массивами в C#.
Общий взгляд
Строкам не повезло. По понятным причинам в первых языках программирования строковому типу уделялось гораздо меньше внимания, чем арифметическому типу или массивам. Поэтому в разных языках строки представлены по-разному и стандарт на строковый тип сложился относительно недавно. Когда говорят о строковом типе, то обычно различают тип, представляющий:
отдельные символы, чаще всего, его называют типом char;строки постоянной длины, часто они представляются массивом символов;строки переменной длины - это, как правило, тип string, соответствующий современному представлению о строковом типе.
Символьный тип char, представляющий частный случай строк длиной 1, полезен во многих задачах. Основные операции над строками - это разбор и сборка. При их выполнении приходится, чаще всего, доходить до каждого символа строки. В языке Паскаль, где был введен тип char, сам строковый тип рассматривался, как char[]-массив символов. При таком подходе получение i-го символа строки становится такой же простой операцией, как и получение i-го элемента массива. Следовательно, эффективно реализуются обычные операции над строками - определение вхождения одной строки в другую, выделение подстроки, замена символов строки. Однако заметьте, представление строки массивом символов хорошо только для строк постоянной длины. Массив не приспособлен к изменению его размеров, вставки или удалению символов (подстрок).
Наиболее часто используемым строковым типом является тип, обычно называемый string, который задает строки переменной длины. Над этим типом допускаются операции поиска вхождения одной строки в другую, операции вставки, замены и удаления подстрок.
Ограниченная универсальность
Хорошо, когда есть свобода. Еще лучше, когда свобода ограничена. Аналогичная ситуация имеет место и с универсальностью. Универсальность следует ограничивать. На типы универсального класса, являющиеся его параметрами, следует накладывать ограничения. Звучит парадоксально, но, наложив ограничения на типы, программист получает гораздо большую свободу в работе с объектами этих типов.
Если немного подумать, то это совершенно естественная ситуация. Когда имеет место неограниченная универсальность, над объектами типов можно выполнять только те операции, которые допускают все типы, - в C# это эквивалентно операциям, разрешенным над объектами типа object, прародителя всех типов. В нашем предыдущем примере, где речь шла о свопинге, над объектами выполнялась единственная операция присваивания. Поскольку присваивание внутри одного типа разрешено для всех типов, то неограниченная универсальность приемлема в такой ситуации. Но что произойдет, если попытаться выполнить сложение элементов, сравнение их или даже простую проверку элементов на равенство? Немедленно возникнет ошибка еще на этапе компиляции. Эти операции не разрешены для всех типов, поэтому в случае компиляции такого проекта ошибка могла бы возникнуть на этапе выполнения, когда вместо формального типа появился бы тип конкретный, не допускающий подобную операцию. Нельзя ради универсальности пожертвовать одним из важнейших механизмов C# и Framework .Net - безопасностью типов, поддерживаемой статическим контролем типов. Именно поэтому неограниченная универсальность существенно ограничена. Ее ограничивает статический контроль типов. Бывают, разумеется, ситуации, когда необходимо на типы наложить ограничения, позволяющие ослабить границы статического контроля. На практике универсальность почти всегда ограничивается, что, повторяю, дает большую свободу программисту.
В языке C# допускаются три вида ограничений, накладываемых на родовые параметры.
Ограничение наследования. Это основный вид ограничений, указывающий, что тип T является наследником некоторого класса и ряда интерфейсов. Следовательно, над объектами типа T можно выполнять все операции, заданные базовым классом и интерфейсами. Эти операции статический контроль типов будет разрешать и обеспечивать для них интеллектуальную поддержку, показывая список разрешенных операций. Ограничение наследования позволяет выполнять над объектами больше операций, чем в случае неограниченной универсальности. Синтаксически ограничение выглядит так: where T: BaseClass, I1, ...Ik.Ограничение конструктора. Это ограничение указывает, что тип T имеет конструктор без аргументов и, следовательно, позволяет создавать объекты типа T. Синтаксически ограничение выглядит так: where T: new().Ограничение value/reference. Это ограничение указывает, к значимым или к ссылочным типам относится тип T. Для указания значимого типа задается слово struct, для ссылочных - class. Так что синтаксически этот тип ограничений выглядит так: where T: struct.
Возникает законный вопрос: насколько полна предлагаемая система ограничений? Конечно, речь идет о практической полноте, а не о математически строгих определениях. С позиций практики систему хотелось бы дополнить, в первую очередь, введением ограничений операций, указывающим допустимые знаки операций в выражениях над объектами соответствующего типа. Хотелось бы, например, указать, что к объектам типа T применима операция сложения + или операция сравнения <. Позже я покажу, как можно справиться с этой проблемой, но предлагаемое решение довольно сложно. Наличие ограничения операций намного элегантнее решало бы эту проблему.
Опасные преобразования и методы класса Convert
Явно выполняемые преобразования по определению относятся к опасным. Явные преобразования можно выполнять по-разному. Синтаксически наиболее просто выполнить приведение типа - кастинг, явно указав тип приведения, как это сделано в только что рассмотренном примере. Но если это делается в непроверяемом блоке, последствия могут быть самыми печальными. Поэтому такой способ приведения типов следует применять с большой осторожностью. Надежнее выполнять преобразования типов более универсальным способом, используя стандартный встроенный класс Convert, специально спроектированный для этих целей.
В нашем примере четвертый и пятый try-блоки встроены в непроверяемый unchecked-блок. Но опасные преобразования реализуются методами класса Convert, которые сами проводят проверку и при необходимости выбрасывают исключения, что и происходит в нашем случае.
На рис. 4.5 показаны результаты работы процедуры CheckUncheckTest. Их анализ способствует лучшему пониманию рассмотренных нами ситуаций.
Рис. 4.5. Вывод на печать результатов теста CheckUncheckTest
На этом, пожалуй, пора поставить точку в обсуждении системы типов языка C#. За получением тех или иных подробностей, как всегда, следует обращаться к справочной системе.
Опасные вычисления в охраняемых непроверяемых блоках
Такую ситуацию демонстрирует третий try-блок нашего примера, встроенный в непроверяемый unchecked-блок. Здесь участвуют те же самые опасные вычисления, но теперь их корректность не проверяется, они не вызывают исключений, и как следствие, соответствующий catch-блок не вызывается. Результаты вычислений при этом неверны, но никаких уведомлений об этом нет. Это самая плохая ситуация, которая может случиться при работе наших программ.
Заметьте, проверку переполнения в арифметических вычислениях можно включить не только с помощью создания checked-блоков, но и задав свойство checked проекта (по умолчанию, оно выключено). Как правило, это свойство проекта всегда включается в процессе разработки и отладки. В законченной версии проекта свойство вновь отключается, поскольку полная проверка всех преобразований требует определенных накладных расходов, увеличивая время работы; а проверяемые блоки остаются лишь там, где такой контроль действительно необходим.
Область действия проверки или ее отключения можно распространить и на отдельное выражение. В этом случае спецификаторы checked и unchecked предшествуют выражению, заключенному в круглые скобки. Такое выражение называется проверяемым (непроверяемым) выражением, а checked и unchecked рассматриваются как операции, допустимые в выражениях.
Опасные вычисления в охраняемых проверяемых блоках
Такая ситуация возникает в первых двух try-блоках нашего примера. Эти блоки встроены в проверяемый checked-блок. В каждом из них используются опасные вычисления, приводящие к неверным результатам. Так, при присваивании невинного выражения b+1 из-за переполнения переменная b получает значение 0, а не 256. Поскольку вычисление находится в проверяемом блоке, то ошибка обнаруживается и результатом является вызов исключения. Далее, поскольку все это происходит в охраняемом блоке, то управление перехватывается и обрабатывается в соответствующем catch-блоке. Эту ситуацию следует отнести к нормальному, разумно построенному процессу вычислений.
Операции
Еще одним частным случаем являются методы, задающие над объектами-классами бинарную или унарную операцию. Введение в класс таких методов позволяет строить выражения, аналогичные арифметическим и булевым выражениям с обычно применяемыми знаками операций и сохранением приоритетов операций. Синтаксис задания таких методов и детали применения опишу чуть позже при проектировании класса рациональных чисел Rational, где введение операций вполне оправдано.
Операции "+" и "-"
Наряду с методами, над делегатами определены и две операции: "+" и "-", которые являются более простой формой записи добавления делегатов в список вызовов и удаления из списка. Операции заменяют собой методы Combine и Remove. Выше написанные присваивания объекту del1 с помощью этих операций могут быть переписаны в виде:
del1 +=del2; del1 -=del2;
Как видите, запись становится проще, исчезает необходимость в задании явного приведения к типу. Ограничения на del1 и del2, естественно, остаются те же, что и для методов Combine и Remove.
Операции над делегатами. Класс Delegate
Давайте просуммируем то, что уже известно о функциональном типе данных. Ключевое слово delegate позволяет задать определение функционального типа (класса), фиксирующее контракт, которому должны удовлетворять все функции, принадлежащие классу. Функциональный класс можно рассматривать как ссылочный тип, экземпляры которого являются ссылками на функции. Заметьте, ссылки на функции - это безопасные по типу указатели, которые ссылаются на функции с жестко фиксированной сигнатурой, заданной делегатом. Следует также понимать, что это не простая ссылка на функцию. В том случае, когда экземпляр делегата инициирован динамическим методом, то экземпляр хранит ссылку на метод и на объект X, вызвавший этот метод.
Вместе с тем, объявление функционального типа не укладывается в синтаксис, привычный для C#. Хотелось бы писать, как принято:
Delegate FType = new Delegate(<определение типа>)
Но так объявлять переменные этого класса нельзя, и стоит понять, почему. Есть ли вообще класс Delegate? Ответ положителен - есть такой класс. При определении функционального типа, например:
public delegate int FType(int X);
переменная FType принадлежит классу Delegate. Почему же ее нельзя объявить привычным образом? Дело не только в синтаксических особенностях этого класса. Дело в том, что класс Delegate является абстрактным классом. Вот его объявление:
public abstract class Delegate: ICloneable, ISerializable
Для абстрактных классов реализация не определена, и это означает, что нельзя создавать экземпляры класса. Класс Delegate служит базовым классом для классов - наследников. Но создавать наследников могут только компиляторы и системные программы - этого нельзя сделать в программе на C#. Именно поэтому введено ключевое слово delegate, которое косвенно позволяет работать с классом Delegate, создавая уже не абстрактный, а реальный класс. Заметьте, при этом все динамические и статические методы класса Delegate становятся доступными программисту.
Трудно, кажется, придумать, что можно делать с делегатами. Однако, у них есть одно замечательное свойство - их можно комбинировать. Представьте себе, что существует список работ, которые нужно выполнять, в зависимости от обстоятельств, в разных комбинациях. Если функции, выполняющие отдельные работы, принадлежат одному классу, то для решения задачи можно использовать делегатов и использовать технику их комбинирования. Замечу, что возможность комбинирования делегатов появилась, в первую очередь, для поддержания работы с событиями. Когда возникает некоторое событие, то сообщение о нем посылается разным объектам, каждый из которых по-своему обрабатывает событие. Реализуется эта возможность на основе комбинирования делегатов.
В чем суть комбинирования делегатов? Она прозрачна. К экземпляру делегату разрешается поочередно присоединять другие экземпляры делегата того же типа. Поскольку каждый экземпляр хранит ссылку на функцию, то в результате создается список ссылок. Этот список называется списком вызовов (invocation list). Когда вызывается экземпляр, имеющий список вызова, то поочередно, в порядке присоединения, начинают вызываться и выполняться функции, заданные ссылками. Так один вызов порождает выполнение списка работ.
Понятно, что, если есть операция присоединения делегатов, то должна быть и обратная операция, позволяющая удалять делегатов из списка.
Рассмотрим основные методы и свойства класса Delegate. Начнем с двух статических методов - Combine и Remove. Первый из них присоединяет экземпляры делегата к списку, второй - удаляет из списка. Оба метода имеют похожий синтаксис:
Combine(del1, del2) Remove(del1, del2)
Аргументы del1 и del2 должны быть одного функционального класса. При добавлении del2 в список, в котором del2 уже присутствует, будет добавлен второй экземпляр. При попытке удаления del2 из списка, в котором del2 нет, Remove благополучно завершит работу, не выдавая сообщения об ошибке.
Класс Delegate относится к неизменяемым классам, поэтому оба метода возвращают ссылку на нового делегата. Возвращаемая ссылка принадлежит родительскому классу Delegate, поэтому ее необходимо явно преобразовать к нужному типу, которому принадлежат del1 и del2. Обычное использование этих методов имеет вид:
del1 = (<type>) Combine(del1, del2); del1 = (<type>) Remove(del1, del2);
Метод GetInvocationList является динамическим методом класса - он возвращает список вызовов экземпляра, вызвавшего метод. Затем можно устроить цикл foreach, поочередно получая элементы списка. Чуть позже появится пример, поясняющий необходимость подобной работы со списком.
Два динамических свойства Method и Target полезны для получения подробных сведений о делегате. Чаще всего они используются в процессе отражения, когда делегат поступает извне и необходима метаинформация, поставляемая с делегатом. Свойство Method возвращает объект класса MethodInfo из пространства имен Reflection. Свойство Target возвращает информацию об объекте, вызвавшем делегата, в тех случаях, когда делегат инициируется не статическим методом класса, а динамическим, связанным с вызвавшим его объектом.
У класса Delegate, помимо методов, наследуемых от класса Object, есть еще несколько методов, но мы на них останавливаться не будем, они используются не столь часто.
Операции над рациональными числами
Определим над рациональными числами стандартный набор операций - сложение и вычитание, умножение и деление. Реализуем эти операции методами с именами Plus, Minus, Mult, Divide соответственно. Поскольку рациональные числа - это прежде всего именно числа, то для выполнения операций над ними часто удобнее пользоваться привычными знаками операций (+, -, *, /). Язык C# допускает определение операций, заданных указанными символами. Этот процесс называется перегрузкой операций, и мы рассмотрим сейчас, как это делается. Конечно, можно было бы обойтись только перегруженными операциями, но мы приведем оба способа. Пользователь сам будет решать, какой из способов применять в конкретной ситуации - вызывать метод или операцию.
Покажем вначале реализацию метода Plus и операции +:
public Rational Plus(Rational a) { int u,v; u = m*a.n +n*a.m; v= n*a.n; return( new Rational(u, v)); }//Plus public static Rational operator +(Rational r1, Rational r2) { return (r1.Plus(r2)); }
Метод Plus реализуется просто. По правилам сложения дробей вычисляется числитель и знаменатель результата, и эти данные становятся аргументами конструктора, создающего требуемое рациональное число, которое удовлетворяет правилам класса.
Обратите внимание на то, как определяется операция класса. Именем соответствующего метода является сам знак операции, которому предшествует ключевое слово operator. Важно также помнить, что операция является статическим методом класса с атрибутом static.
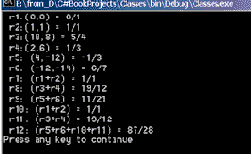
Рис. 16.4. Сложение рациональных чисел
В данном конкретном случае операция реализуется вызовом метода Plus. Как теперь все это работает? Вот пример:
public void TestPlusRational() { Rational r1=new Rational(0,0), r2 = new Rational(1,1); Rational r3=new Rational(10,8), r4 = new Rational(2,6); Rational r5=new Rational(4,-12), r6 = new Rational (-12,-14); Rational r7,r8, r9,r10, r11, r12; r7 = r1.Plus(r2); r8 = r3.Plus(r4); r9 = r5.Plus(r6); r10 = r1+r2; r11 = r3+r4; r12 = r5+r6+r10+r11; r1.PrintRational("r1:(0,0)"); r2.PrintRational("r2:(1,1)"); r3.PrintRational("r3:(10,8)"); r4.PrintRational("r4:(2,6)"); r5.PrintRational("r5: (4,-12)"); r6.PrintRational ("r6: (-12,-14)"); r7.PrintRational("r7: (r1+r2)"); r8.PrintRational ("r8: (r3+r4)"); r9.PrintRational("r9: (r5+r6)"); r10.PrintRational ("r10: (r1+r2)"); r11.PrintRational("r11: (r3+r4)"); r12.PrintRational("r12: (r5+r6+r10+r11)"); }
Обратите внимание на вычисление r12: здесь ощутимо видно преимущество операций, позволяющих записывать сложные выражения в простой форме. Результаты вычислений показаны на рис. 16.4.
Аналогичным образом определим остальные операции над рациональными числами:
public Rational Minus(Rational a) { int u,v; u = m*a.n - n*a.m; v= n*a.n; return( new Rational(u, v)); }//Minus public static Rational operator -(Rational r1, Rational r2) { return (r1.Minus(r2)); } public Rational Mult(Rational a) { int u,v; u = m*a.m; v= n*a.n; return( new Rational(u, v)); }//Mult public static Rational operator *(Rational r1, Rational r2) { return (r1.Mult(r2)); } public Rational Divide(Rational a) { int u,v; u = m*a.n; v= n*a.m; return( new Rational(u, v)); }//Divide public static Rational operator /(Rational r1, Rational r2) { return (r1.Divide(r2)); }
Вот тест, проверяющий работу этих операций:
public void TestOperRational() { Rational r1=new Rational(1,2), r2 = new Rational(1,3); Rational r3, r4, r5, r6 ; r3 = r1- r2; r4 = r1*r2; r5 = r1/r2; r6 = r3+r4*r5; r1.PrintRational("r1: (1,2)"); r2.PrintRational("r2: (1,3)"); r3.PrintRational("r3: (r1-r2)"); r4.PrintRational("r4: (r1*r2)"); r5.PrintRational("r5: (r1/r2)"); r6.PrintRational("r6: (r3+r4*r5)"); }
Результаты работы этого теста показаны на рис. 16.5. Обратите внимание: при перегрузке операций сохраняется общепринятый приоритет операций. Поэтому при вычислении выражения r3+r4*r5 вначале будет выполняться умножение рациональных чисел, а потом уже сложение.
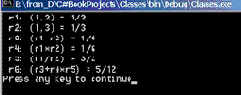
Рис. 16.5. Операции и выражения над рациональными числами
Операции над строками
Над строками определены следующие операции:
присваивание (=);две операции проверки эквивалентности (==) и (!=);конкатенация или сцепление строк (+);взятие индекса ([]).
Начну с присваивания, имеющего важную особенность. Поскольку string - это ссылочный тип, то в результате присваивания создается ссылка на константную строку, хранимую в "куче". С одной и той же строковой константой в "куче" может быть связано несколько переменных строкового типа. Но эти переменные не являются псевдонимами - разными именами одного и того же объекта. Дело в том, что строковые константы в "куче" не изменяются (о неизменяемости строкового типа будем далее говорить подробно), поэтому когда одна из переменных получает новое значение, она связывается с новым константным объектом в "куче". Остальные переменные сохраняют свои связи. Для программиста это означает, что семантика присваивания строк аналогична семантике значимого присваивания.
В отличие от других ссылочных типов операции, проверяющие эквивалентность, сравнивают значения строк, а не ссылки. Эти операции выполняются как над значимыми типами.
Бинарная операция "+" сцепляет две строки, приписывая вторую строку к хвосту первой.
Возможность взятия индекса при работе со строками отражает тот приятный факт, что строку можно рассматривать как массив и получать без труда каждый ее символ. Каждый символ строки имеет тип char, доступный только для чтения, но не для записи.
Вот пример, в котором над строками выполняются данные операции:
public void TestOpers() { //операции над строками string s1 ="ABC", s2 ="CDE"; string s3 = s1+s2; bool b1 = (s1==s2); char ch1 = s1[0], ch2=s2[0]; Console.WriteLine("s1={0}, s2={1}, b1={2}," + "ch1={3}, ch2={4}", s1,s2,b1,ch1,ch2); s2 = s1; b1 = (s1!=s2); ch2 = s2[0]; Console.WriteLine("s1={0}, s2={1}, b1={2}," + "ch1={3}, ch2={4}", s1,s2,b1,ch1,ch2); //Неизменяемые значения s1= "Zenon"; //s1[0]='L'; }
Операции над строками
Над строками этого класса определены практически те же операции с той же семантикой, что и над строками класса String:
присваивание (=);две операции проверки эквивалентности (==) и (!=);взятие индекса ([]).
Операция конкатенации (+) не определена над строками класса StringBuilder, ее роль играет метод Append, дописывающий новую строку в хвост уже существующей.
Со строкой этого класса можно работать как с массивом, но, в отличие от класса String, здесь уже все делается как надо: допускается не только чтение отдельного символа, но и его изменение. Рассмотрим с небольшими модификациями наш старый пример:
public void TestStringBuilder() { //Строки класса StringBuilder //операции над строками StringBuilder s1 =new StringBuilder("ABC"), s2 =new StringBuilder("CDE"); StringBuilder s3 = new StringBuilder(); //s3= s1+s2; s3= s1.Append(s2); bool b1 = (s1==s3); char ch1 = s1[0], ch2=s2[0]; Console.WriteLine("s1={0}, s2={1}, b1={2}," + "ch1={3}, ch2={4}", s1,s2,b1,ch1,ch2); s2 = s1; b1 = (s1!=s2); ch2 = s2[0]; Console.WriteLine("s1={0}, s2={1}, b1={2}," + "ch1={3}, ch2={4}", s1,s2,b1,ch1,ch2); StringBuilder s = new StringBuilder("Zenon"); s[0]='L'; Console.WriteLine(s); }//TestStringBuilder
Этот пример демонстрирует возможность выполнения над строками класса StringBuilder тех же операций, что и над строками класса String. В результате присваивания создается дополнительная ссылка на объект, операции проверки на эквивалентность работают со значениями строк, а не со ссылками на них. Конкатенацию можно заменить вызовом метода Append. Появляется новая возможность - изменять отдельные символы строки. (Для того чтобы имя класса StringBuilder стало доступным, в проект добавлено предложение using System.Text, ссылающееся на соответствующее пространство имен.)
Операции отношения
Операции отношения можно просто перечислить - в объяснениях они не нуждаются. Всего операций 6 (==, !=, <, >, <=, >= ). Для тех, кто не привык работать с языком C++, стоит обратить внимание на запись операций "равно" и "не равно".
Операции проверки типов
Операции проверки типов is и as будут рассмотрены в последующих лекциях. (см. лекцию 19).
Операции сдвига
Операции сдвига вправо ">>" и сдвига влево "<<" в обычных вычислениях применяются редко. Они особенно полезны, если данные рассматриваются как строка битов. Результатом операции является сдвиг строки битов влево или вправо на K разрядов. В применении к обычным целым положительным числам сдвиг вправо равносилен делению нацело на 2K, а сдвиг влево - умножению на 2K. Для отрицательных чисел сдвиг влево и деление дают разные результаты, отличающиеся на единицу. В языке C# операции сдвига определены только для некоторых целочисленных типов - int, uint, long, ulong. Величина сдвига должна иметь тип int. Вот пример применения этих операций:
/// <summary> /// операции сдвига /// </summary> public void Shift() { int n = 17,m =3, p,q; p= n>>2; q = m<<2; Console.WriteLine("n= " + n + "; m= " + m + "; p=n>>2 = "+p + "; q=m<<2 " + q); long x=-75, y =-333, u,v,w; u = x>>2; v = y<<2; w = x/4; Console.WriteLine("x= " + x + "; y= " + y + "; u=x>>2 = "+u + "; v=y<<2 " + v + "; w = x/4 = " + w); }//Shift
Операции sizeof и typeof
Операция sizeof возвращает размер значимых типов, заданный в байтах. Пояснения требуют некоторые особенности ее применения. Она должна выполняться только в небезопасных блоках. Поэтому проект, в котором она может использоваться, должен быть скомпилирован с включенным свойством /unsafe. На рис. 6.1 показано, как на странице свойств проекта можно включить это свойство:
Далее необходимо создать небезопасный блок, например, метод класса, помеченный как unsafe, в котором уже можно вызывать эту функцию (операцию). Приведу пример такого метода, созданного в классе Testing:
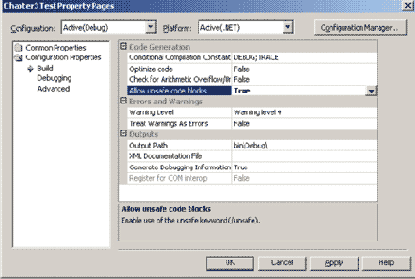
Рис. 6.1. Включение свойства /unsafe
/// <summary> /// определение размеров и типов /// </summary> unsafe public static void SizeMethod() { Console.WriteLine("Размер типа Boolean = " + sizeof(bool)); Console.WriteLine("Размер типа double = " + sizeof(double)); Console.WriteLine("Размер типа char = " + sizeof(System.Char)); int b1=1; Type t = b1.GetType(); Console.WriteLine("Тип переменной b1: {0}", t); //Console.WriteLine("Размер переменной b1: {0}", sizeof(t)); }//SizeMethod
В этом примере операция применяется к трем встроенным типам - bool, double, char. Консольный вывод дает в качестве результата значения: 1, 8 и 2. Обращаю внимание на то, что аргументом операции может быть только имя типа. Попытка применить эту операцию к переменной t типа Type, имеющей значение System.Int32, приводит к ошибке компиляции.
Операция typeof, примененная к своему аргументу, возвращает его тип. И здесь в роли аргумента может выступать имя класса, как встроенного, так и созданного пользователем. Возвращаемый операцией результат имеет тип Type. К экземпляру класса применять операцию нельзя, но зато для экземпляра можно вызвать метод GetType, наследуемый всеми классами, и получить тот же результат, что дает typeof с именем данного класса. Такой альтернативный способ получения типа по экземпляру класса int показан в приведенном выше программном фрагменте. А сейчас я приведу фрагмент, где используется вызов операции typeof:
t = typeof(Class1); Console.WriteLine("Тип класса Class1: {0}", t); t = typeof(Testing); Console.WriteLine("Тип класса Testing: {0}", t);
Операции "упаковать" и "распаковать" (boxing и unboxing).
Примеры
В нашем следующем примере демонстрируется применение обеих операций - упаковки и распаковки. Поскольку формальный аргумент процедуры Back принадлежит классу Object, то при передаче фактического аргумента значимого типа происходит упаковка значения в объект. Этот объект и возвращается процедурой. Его динамический тип определяется тем объектом памяти, на который указывает ссылка. Когда возвращаемый результат присваивается переменной значимого типа, то, несмотря на совпадение типа переменной с динамическим типом объекта, необходимо выполнить распаковку, "содрать" объектную упаковку и вернуть непосредственное значение. Вот как выглядит процедура Back и тестирующая ее процедура BackTest из класса Testing:
/// <summary> /// Возвращает переданный ему аргумент. /// Фактический аргумент может иметь произвольный тип. /// Возвращается всегда объект класса object. /// Клиент, вызывающий метод, должен при необходимости /// задать явное преобразование получаемого результата /// </summary> /// <param name="any"> Допустим любой аргумент</param> /// <returns></returns> object Back(object any) { return(any); } /// <summary> /// Неявное преобразование аргумента в тип object /// Явное приведение типа результата. /// </summary> public void BackTest() { ux = (uint)Back(ux); WhoIsWho("ux",ux); s1 = (string)Back(s); WhoIsWho("s1",s1); x =(int)(uint)Back(ux); WhoIsWho("x",x); y = (float)(double)Back(11 + 5.55 + 5.5f); WhoIsWho("y",y); }
Обратите внимание, что если значимый тип в левой части оператора присваивания не совпадает с динамическим типом объекта, то могут потребоваться две операции приведения. Вначале нужно распаковать значение, а затем привести его к нужному типу, что и происходит в двух последних операторах присваивания. Приведу результаты вывода на консоль, полученные при вызове процедуры BackTest в процедуре Main.
Рис. 3.2. Вывод на печать результатов теста BackTest
Две двойственные операции "упаковать" и "распаковать" позволяют, в зависимости от контекста, рассматривать значимые типы как ссылочные, переменные как объекты, и наоборот.
Операции "увеличить" и "уменьшить" (increment, decrement)
Операции "увеличить на единицу" и "уменьшить на единицу" могут быть префиксными и постфиксными. К высшему приоритету относятся постфиксные операции x++ и x--. Префиксные операции имеют на единицу меньший приоритет. Главной особенностью как префиксных, так и постфиксных операций является побочный эффект, в результате которого значение x увеличивается (++) или уменьшается (--) на единицу. Для префиксных (++x, --x) операций результатом их выполнения является измененное значение x, постфиксные операции возвращают в качестве результата значение x до изменения. Приведу пример применения этих операций, дополнив метод Express новым фрагментом:
//операции increment и decrement //Следующее выражение допустимо, но писать подобное никогда не следует in1 = ++in1 +in1+ in1++; //in2 = ++in1 + in1++ + in1; Console.WriteLine(" in1= " + in1);
Обратите внимание, что хотя у постфиксной операции высший приоритет, это вовсе не означает, что при вычислении выражения вначале выполнится операция in1++, затем ++in1, и только потом будет проводиться сложение. Нет, вычисления проводятся в том порядке, в котором они написаны. Поскольку на входе значение in1 было равно 6, то выражение будет вычисляться следующим образом:
7(7) + 7 + 7(8),
где в скобках записан побочный эффект операции. Так что консольный вывод даст следующий результат:
in1 = 21
Операциями "увеличить" и "уменьшить" не следует злоупотреблять. Уже оператор, приведенный в нашем фрагменте, сложен для понимания из-за побочного эффекта. Понимаете ли вы, что при изменении порядка записи слагаемых, как это сделано в закомментированном операторе, результат вычисления выражения будет уже не 21, а 22?
|
Разный приоритет префиксных и постфиксных операций носит условный характер. Эти операции применимы только к переменным, свойствам и индексаторам класса, то есть к выражениям, которым отведена область памяти. В языках C++ и C# такие выражения называются l-value, поскольку они могут встречаться в левых частях оператора присваивания. Как следствие, запись в C# выражения < --x++ > приведет к ошибке. Едва лишь к x слева или справа приписана одна из операций, выражение перестает принадлежать к классу l-value выражений, и вторую операцию приписать уже нельзя. |
Операция new
Пора вернуться к основной теме - операциям, допустимым в языке C#. Последней из еще не рассмотренных операций высшего уровня приоритета является операция new. Ключевое слово new используется в двух контекстах - как модификатор и как операция в инициализирующих выражениях объявителя. Во втором случае результатом выполнения операции new является создание нового объекта и вызов соответствующего конструктора. Примеров подобного использования операции new было приведено достаточно много, в том числе и в этой лекции.
Операция приведения к типу
Осталось рассмотреть еще одну операцию - приведение к типу. Эта операция первого приоритета имеет следующий синтаксис:
(type) <унарное выражение>
Она задает явное преобразование типа, определенного выражением, к типу, указанному в скобках. Чтобы операция была успешной, необходимо, чтобы такое явное преобразование существовало. Напомню, существуют явные преобразования внутри арифметического типа, но не существует, например, явного преобразования арифметического типа в тип bool. При определении пользовательских типов для них могут быть заданы явные преобразования в другие, в том числе встроенные, типы. О явных преобразованиях говорилось достаточно много, приводились и примеры. Поэтому ограничусь совсем простым примером:
//cast int p; p = (int)x; //b = (bool)x;
В данном примере явное преобразование из типа double в тип int выполняется, а преобразование double в тип bool приводит к ошибке, потому и закомментировано.
Оператор for
Наследованный от С++ весьма удобный оператор цикла for обобщает известную конструкцию цикла типа арифметической прогрессии. Его синтаксис:
for(инициализаторы; условие; список_выражений) оператор
Оператор, стоящий после закрывающей скобки, задает тело цикла. В большинстве случаев телом цикла является блок. Сколько раз будет выполняться тело цикла, зависит от трех управляющих элементов, заданных в скобках. Инициализаторы задают начальное значение одной или нескольких переменных, часто называемых счетчиками или просто переменными цикла. В большинстве случаев цикл for имеет один счетчик, но часто полезно иметь несколько счетчиков, что и будет продемонстрировано в следующем примере. Условие задает условие окончания цикла, соответствующее выражение при вычислении должно получать значение true или false. Список выражений, записанный через запятую, показывает, как меняются счетчики цикла на каждом шаге выполнения. Если условие цикла истинно, то выполняется тело цикла, затем изменяются значения счетчиков и снова проверяется условие. Как только условие становится ложным, цикл завершает свою работу. В цикле for тело цикла может ни разу не выполняться, если условие цикла ложно после инициализации, а может происходить зацикливание, если условие всегда остается истинным. В нормальной ситуации тело цикла выполняется конечное число раз.
Счетчики цикла зачастую объявляются непосредственно в инициализаторе и соответственно являются переменными, локализованными в цикле, так что после завершения цикла они перестают существовать.
В тех случаях, когда предусматривается возможность преждевременного завершения цикла с помощью одного из операторов перехода, счетчики объявляются до цикла, что позволяет анализировать их значения при выходе из цикла.
В качестве примера рассмотрим классическую задачу: является ли строка текста палиндромом. Напомню, палиндромом называется симметричная строка текста, читающаяся одинаково слева направо и справа налево. Для ее решения цикл for подходит наилучшим образом: здесь используются два счетчика - один возрастающий, другой убывающий. Вот текст соответствующей процедуры:
/// <summary> /// Определение палиндромов.Демонстрация цикла for /// </summary> /// <param name="str">текст</param> /// <returns>true - если текст является палиндромом</returns> public bool Palindrom(string str) { for (int i =0,j =str.Length-1; i<j; i++,j--) if(str[i]!=str[j]) return(false); return(true); }//Palindrom
Оператор goto
Оператор goto имеет простой синтаксис и семантику:
goto [метка|case константное_выражение|default];
Все операторы языка C# могут иметь метку - уникальный идентификатор, предшествующий оператору и отделенный от него символом двоеточия. Передача управления помеченному оператору - это классическое использование оператора goto. Два других способа использования goto (передача управления в case или default-ветвь) используются в операторе switch, о чем шла речь выше.
"О вреде оператора goto" и о том, как можно обойтись без него, писал еще Эдгар Дейкстра при обосновании принципов структурного программирования.
|
Я уже многие годы не применяю этот оператор и считаю, что хороший стиль программирования не предполагает использования этого оператора в C# ни в каком из вариантов - ни в операторе switch, ни для организации безусловных переходов. |